RESEARCH · 2026-05-21 · ~20 мин
Что считают 5-часовые лимиты в ChatGPT и Claude — и почему модели стоят по-разному
Из чего складывается цена ответа LLM — разбор на open-weight моделях
Суть
Каждый раз, открывая дропдаун с выбором модели, ты видишь несколько классов: маленькую и быструю, среднюю и флагманскую. Ещё практически у всех есть переключатель Thinking.
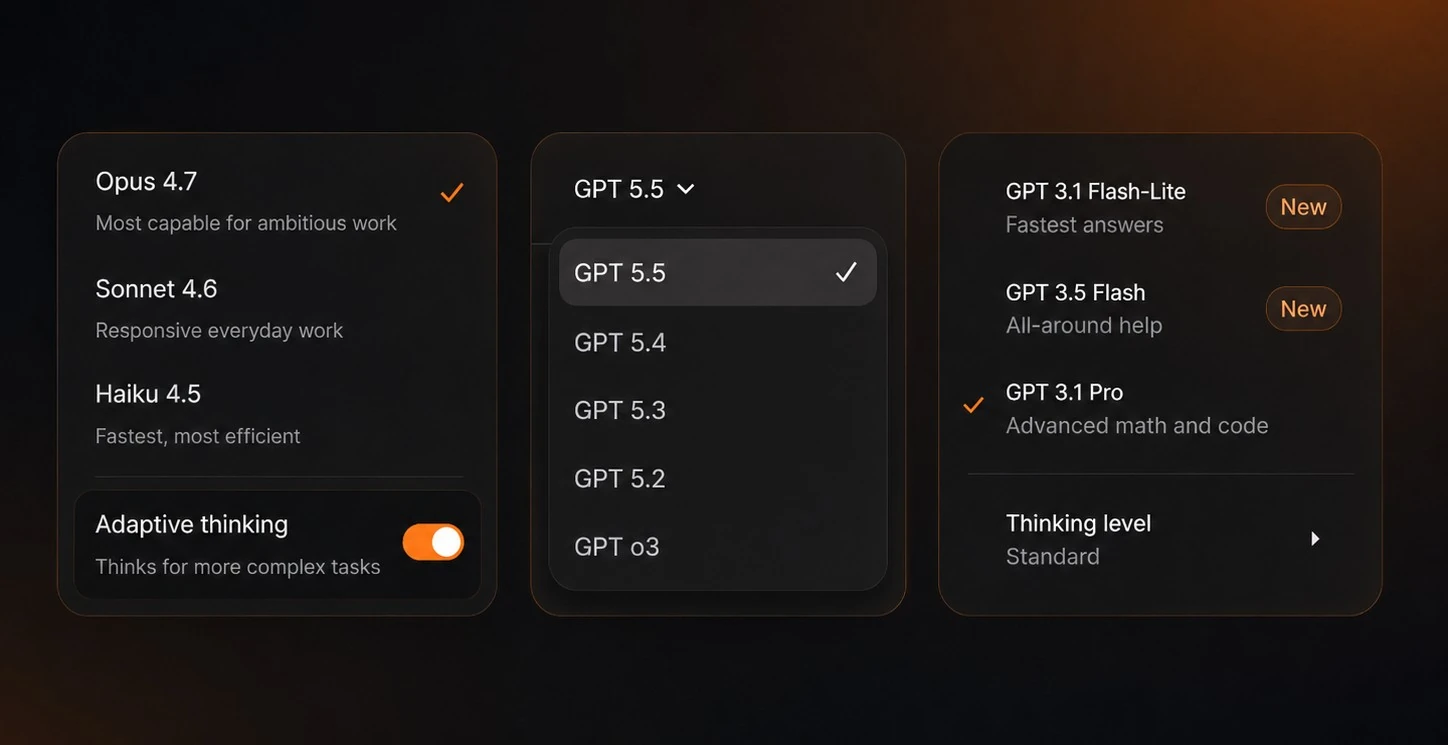
У каждой свой ценник и влияние на 5-часовые лимиты. Разрыв между крайними классами — это не проценты, а разы. Возникает закономерный вопрос: почему дорогая модель дороже?
Короткий ответ: потому что каждый ответ модели использует больше вычислительных мощностей датацентра. А 5-часовой лимит, который ты видишь у себя на экране, — это удобная, понятная и простая визуализация, за которой скрывается вся сложность, про которую мы поговорим ниже.
Очень грубая формула стоимости одного ответа выглядит так:
стоимость ответа считается примерно так ≈
input-токены
+ output-токены
+ скрытые reasoning-токены
+ память под контекст
+ serving overheadЕсли коротко по слагаемым:
- Токен — это кусочек текста, которым оперирует модель, примерно слово или часть слова; и считается, и тарифицируется всё именно в токенах
- Input — те токены, что ты отправил модели, output — те токены, что она написала в ответ
- Reasoning-токены — её внутреннее размышление до видимого ответа
- Serving overhead — накладные расходы провайдера на то, чтобы держать модель запущенной и готовой отвечать: очереди, маршрутизация и простаивающие между запросами GPU
Каждое слагаемое — это отдельный кусок GPU-времени и GPU-памяти, за который кто-то платит. Дальше разберём их по очереди.
Одна оговорка перед стартом. Считать такую математику удобнее всего на примере GPT — модель знакомая, ценник у всех перед глазами. Но есть проблема: OpenAI не раскрывает ни архитектуру, ни размер своих моделей. С Claude та же история. Проверить на них формулу нельзя — мы просто не знаем входных чисел.
Поэтому разбирать будем на open-weight моделях — Llama и DeepSeek. У них опубликованы и размер, и архитектура, а цену выставляет конкурентный рынок провайдеров. На них математика сходится в числах, которые можно перепроверить руками. А потом перенесём логику на закрытые флагманы.
Почему open-weight — честный бенчмарк
Open-weight — это модель, у которой веса выложены в открытый доступ. Llama от Meta — как раз такая: файлы с весами можно скачать, а лицензия разрешает коммерческое использование.
Размер модели измеряют в миллиардах параметров — отсюда 8B, 70B,
405B (от англ. billion). И этот размер имеет значение — чтобы
запустить модель, нужно железо:
- Llama 3.1 8B — заводится на хорошем ноутбуке
- Llama 3.1 70B — нужен сервер с парой видеокарт
- Llama 3.1 405B — кластер примерно из 8 штук H100 (датацентровая GPU NVIDIA с 80 ГБ VRAM на карту), сотни тысяч долларов железа

Сами себе такое поднять могут меньшинство, потому что узел из 8 H100 стоит около 300–400 тысяч долларов. Большинство просто берёт inference-провайдера — компанию, которая держит модель запущенной и продаёт доступ к ней. Inference — это и есть работа модели на ответах, в отличие от обучения. Таких провайдеров много: Together AI, Fireworks, DeepInfra, Groq, Cerebras. Каждый поднимает у себя те же открытые веса и продаёт доступ к модели по токенам.
И вот ключевой момент. Веса у всех провайдеров одинаковые, поэтому конкурируют они между собой за одного и того же клиента. Монополии нет. А значит, цена на Llama не может улететь в космос — она прижата к реальной физике обслуживания плюс скромная маржа провайдера.
У закрытых моделей всё иначе. Веса GPT, Claude и Gemini знают только OpenAI, Anthropic и Google — и только они хостят эти модели. В их ценник зашито сразу всё:
- compute — собственно вычисления, работа GPU
- монопольная маржа
- окупаемость многолетнего research
- стоимость обучения
- alignment — донастройка модели на безопасные и полезные ответы
Одной строкой прайса, без расшифровки:
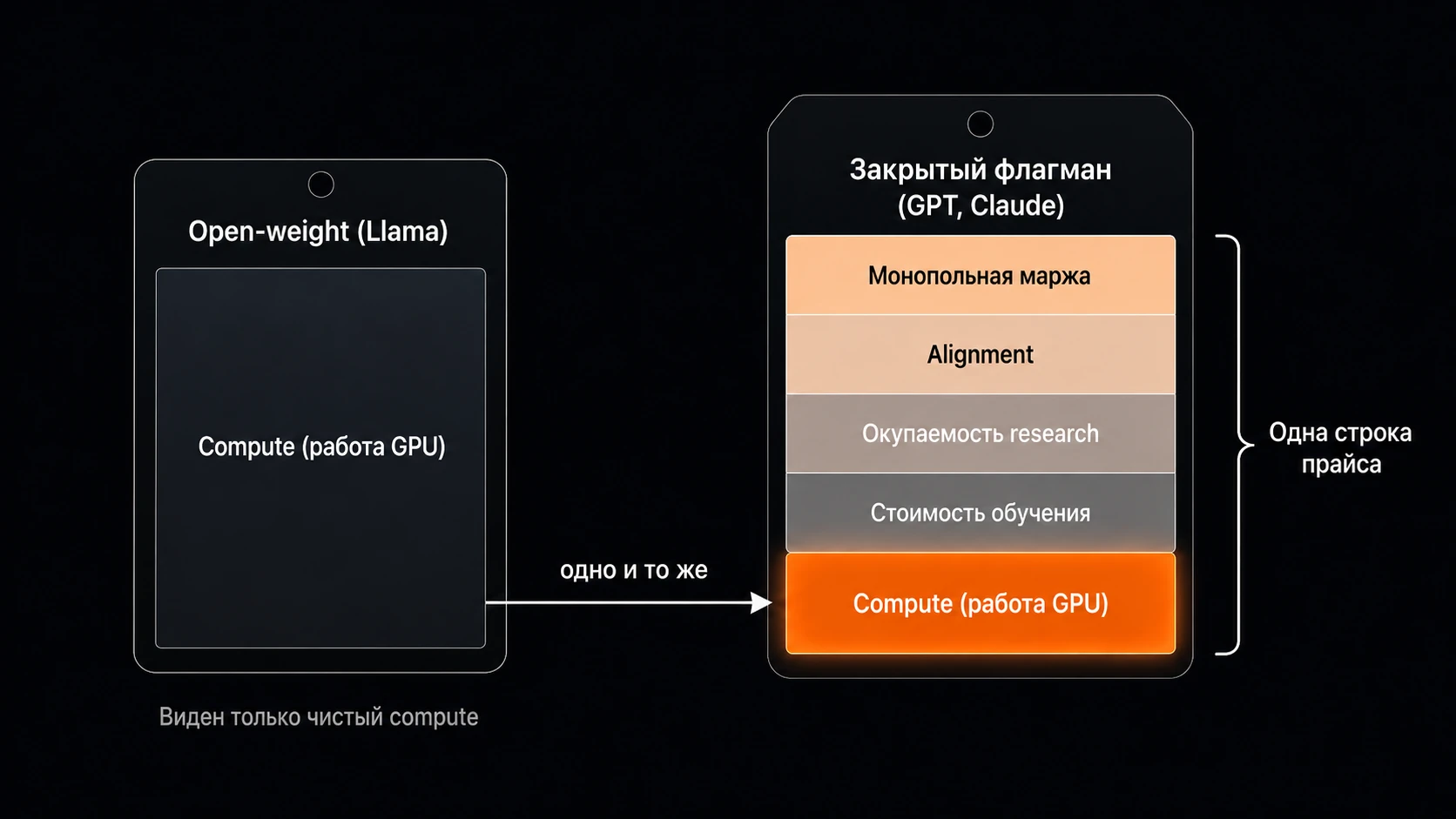
Поэтому на Llama видна голая цена compute — без всего, что налеплено сверху. Закрытый флагман — это compute плюс всё остальное, и разделить их снаружи нельзя. Всё, что мы посчитаем дальше на Llama и DeepSeek — это честная физика, нижняя граница. А на флагманах мы будем уже интерпретировать.
Большая модель дороже на каждый токен
Когда модель генерирует следующий токен, она прогоняет контекст через всю нейросеть и считает вероятности — какой токен идёт дальше. Размер этой нейросети измеряют в параметрах — это настроенные при обучении числа-коэффициенты, и их в модели миллиарды; именно их считают, когда говорят «модель на 70 миллиардов». Чем больше параметров, тем больше операций уходит на один токен.
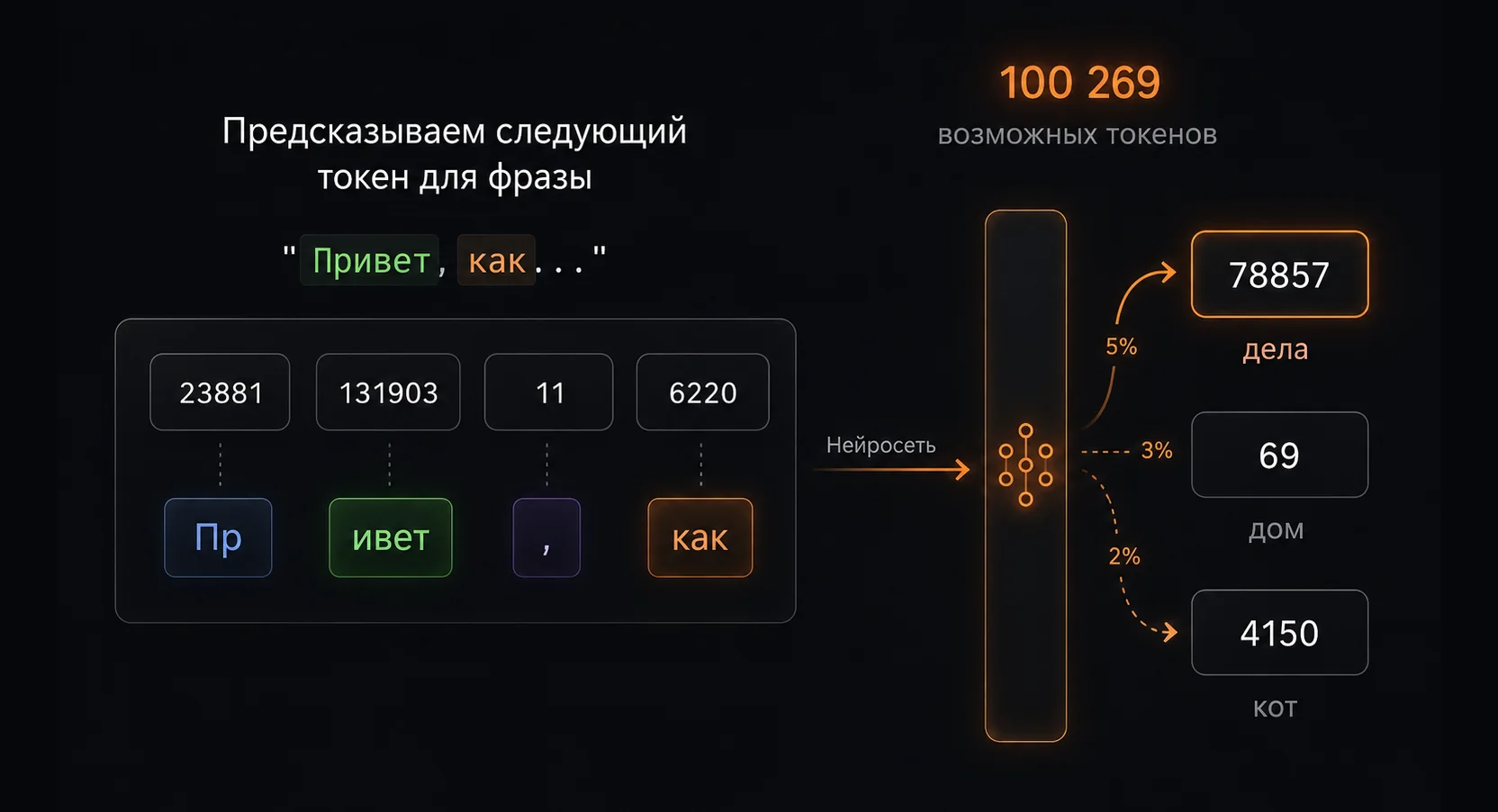
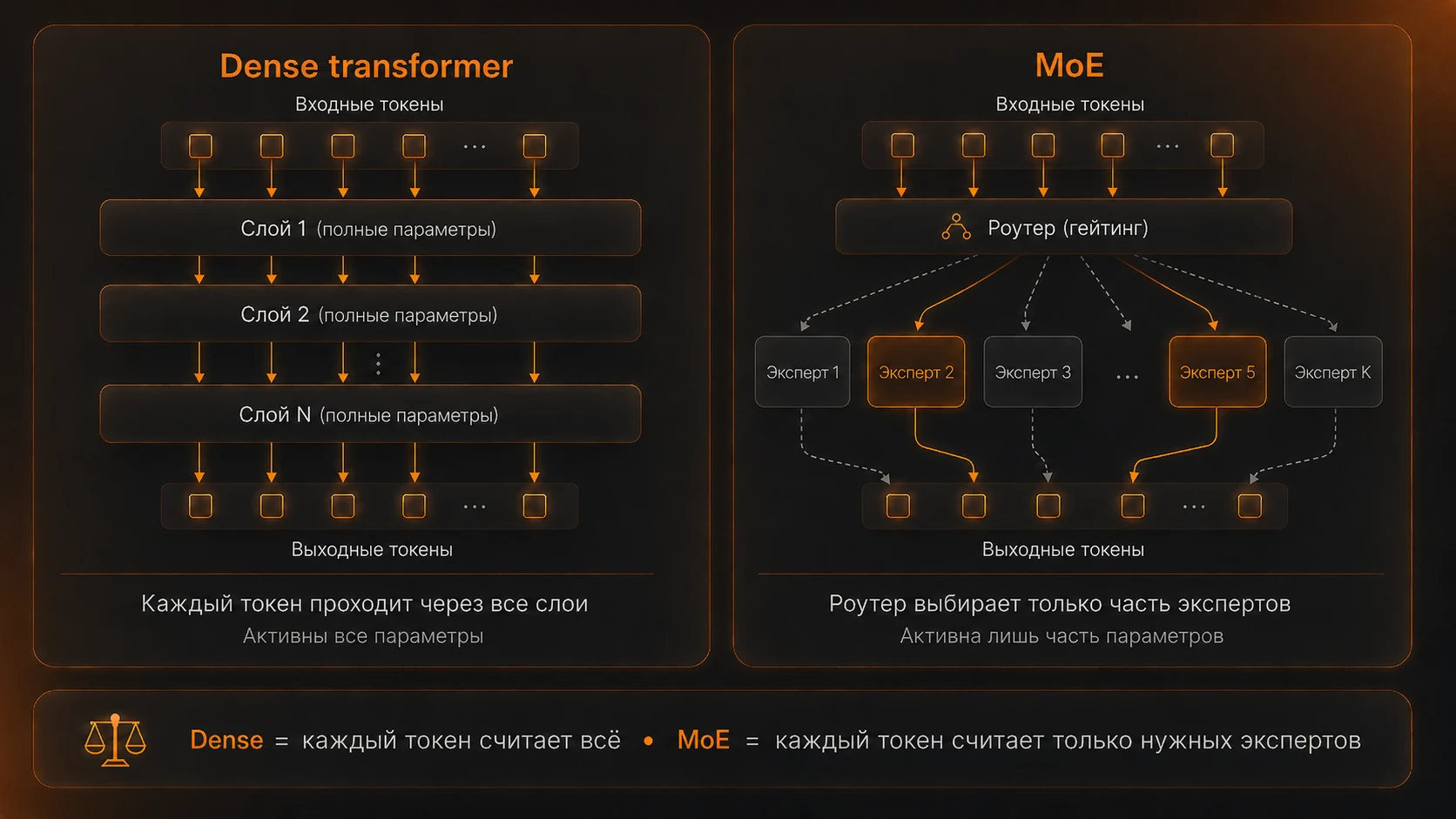
Здесь стоит сразу развести два класса современных больших моделей. Dense — классический трансформер: на каждый токен задействована вся сеть, все параметры считаются.
MoE (Mixture of Experts) — модель, где параметры разделены на «экспертов», и на каждый токен включается только их часть. Llama 3.1 — dense, DeepSeek V3.1 — MoE. Разница принципиальна для счёта, и подробно разберём её в следующей главе. А пока возьмём dense — там оценка считается проще всего.
Для dense-трансформера есть грубая оценка:
FLOPs/token ≈ 2 × количество параметровТо есть условные 20B параметров — это примерно 40 миллиардов операций на токен. 200B — уже около 400 миллиардов. Чем больше параметров, тем дороже каждый сгенерированный токен.
Кроме количества параметров, на скорость ответа влияет ещё глубина модели — количество слоёв, которые токен проходит последовательно. Llama 3.1 70B имеет 80 слоёв, Llama 3.1 405B — 126. Слои нельзя параллелить — каждый следующий ждёт результата предыдущего. Поэтому крупные модели не просто дороже на токен, но и физически медленнее за счёт этой sequential chain.
Несколько оговорок к формуле:
- MoE-модели. Для них формула считается по активным параметрам, а не по всем. Что это значит — разберём в следующей секции.
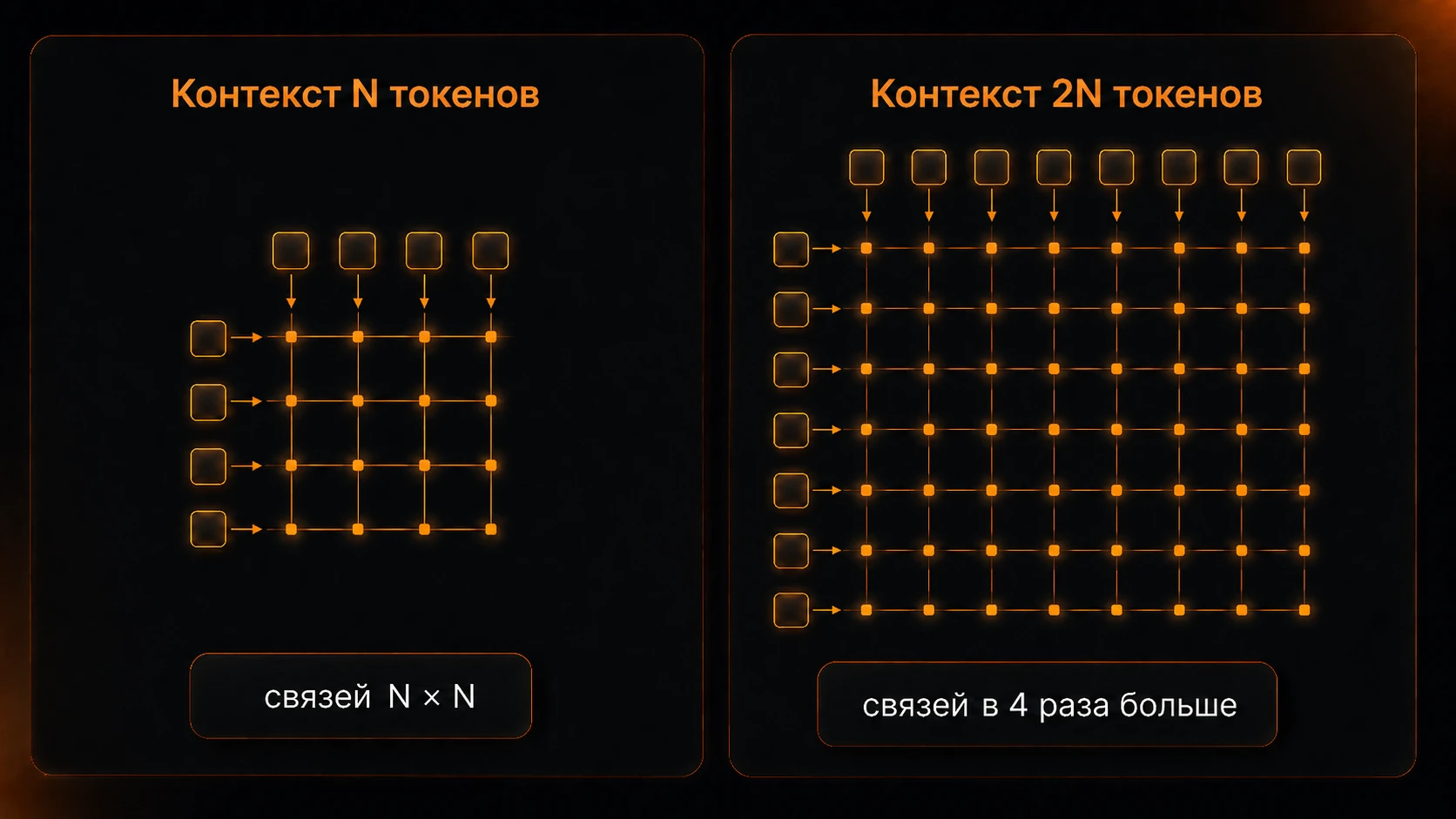
- Attention. Формула его не учитывает — а это механизм, которым модель на каждом токене сверяется со всеми остальными токенами контекста. Из-за этого «каждый с каждым» вычислений на attention тем больше, чем длиннее контекст, и растут они быстрее самой длины: удвоил контекст — затраты на вычисление attention увеличились в 4 раза. На коротком промпте этим можно пренебречь, на контексте в 100k+ токенов — уже нет.
Проверим формулу на реальных числах
Llama 3.1 — вся dense, размеры опубликованы, цены берём у Together AI. Это снапшот конца 2024 — последний период, когда вся тройка 8B / 70B / 405B продавалась у одного провайдера на одной площадке. Тройку используем как чистую иллюстрацию формулы 2N: одна архитектура, одна линейка, один прайс-лист, одна дата.
Together AI · снапшот конца 2024
Модель в 50 раз больше — а токен только в 19 раз дороже
График показывает рост цены за токен, а таблица фиксирует точные цифры Together AI
Во сколько раз дороже токен
Бар показывает, во сколько раз токен дороже, чем у Llama 8B. Цена растёт с размером модели — но медленнее самого размера.
| Модель | Параметры | Операций на токен (FLOPs ≈ 2N) | Цена за 1M токенов | × к 8B |
|---|---|---|---|---|
| Llama 3.1 8B | 8B | 16B | $0,18 | 1× |
| Llama 3.1 70B | 70B | 140B | $0,88 | 4,9× |
| Llama 3.1 405B | 405B | 810B | $3,50 | 19,4× |
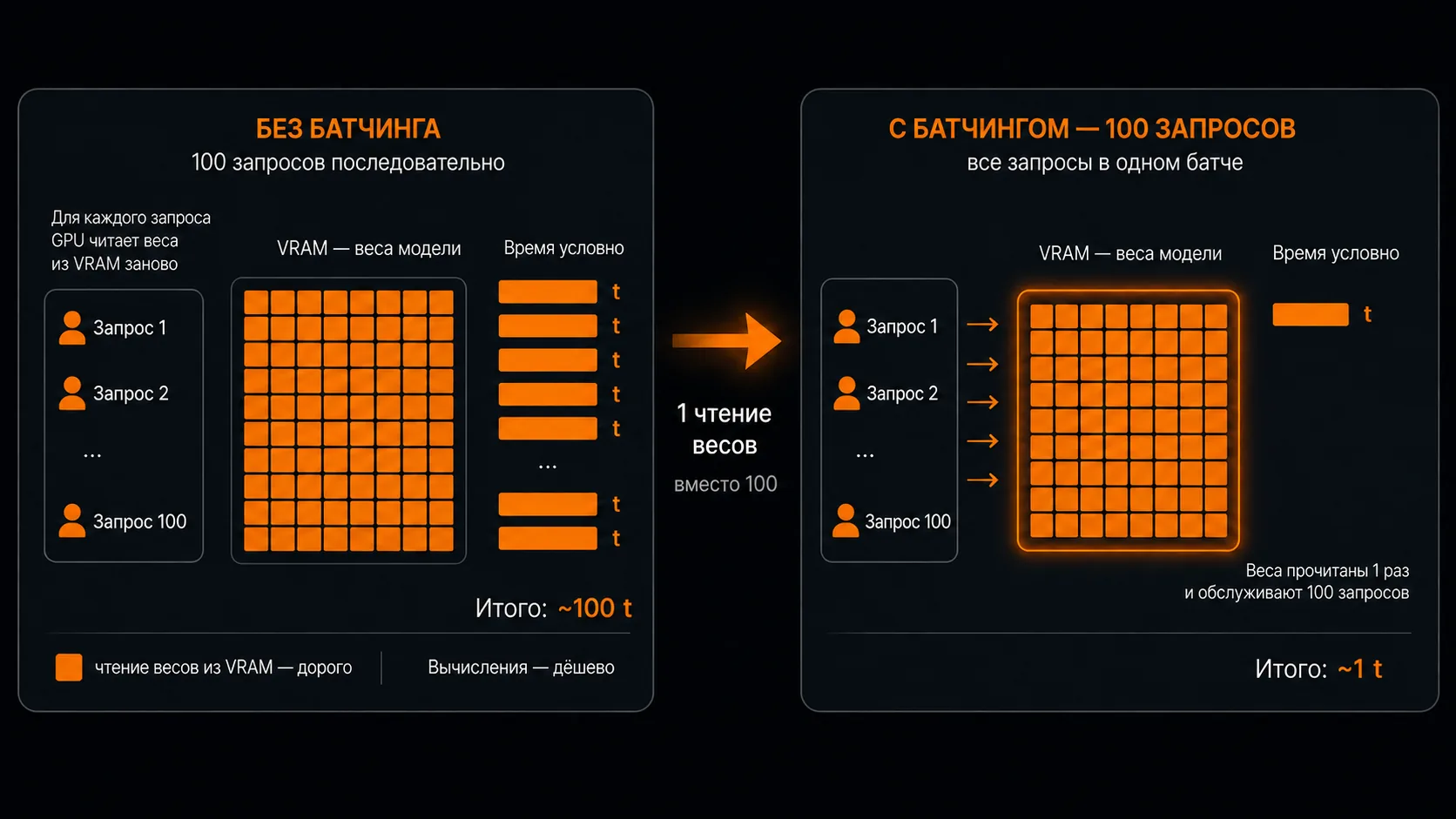
Цена растёт с размером, как и предсказывает формула FLOPs/token ≈ 2N, но медленнее: ×50 по параметрам против ×19 по цене. Разницу съедает батчинг — у крупных моделей стоимость железа размазывается по большему числу запросов.
Параметры выросли в 50 раз — с 8B до 405B. Цена выросла в 19 раз. Не строго линейно — и тут включается батчинг: провайдер складывает запросы многих пользователей в одну пачку и прогоняет через GPU разом. Крупные модели батчатся выгоднее, и стоимость их дорогого железа размазывается по большему числу запросов. Но направление ровно то, что обещает формула 2N — больше модель, дороже токен.
И ещё один угол, который легко упустить за ценой. Маленькая модель не просто дешевле — она ещё и быстрее: меньше операций на токен — меньше латентность, то есть задержка ответа. Флагман на тот же вопрос ответит и дороже, и медленнее. В агентных сценариях — когда модель работает в цикле «шаг → результат → следующий шаг», и так десятки раз, — это бьёт особенно больно: задержки складываются. Да и в обычном продакшне пользователь ждёт ответ сейчас.
Total ≠ active: откуда «модель на N триллионов»
В прошлой главе формула FLOPs ≈ 2N работала для dense, где N — все
параметры модели. У MoE (Mixture of Experts) она остаётся той
же, но N в ней — только active: те параметры, через которые реально проходит каждый токен.
Остальные на этом токене просто не считаются.
Напомним: в dense-модели на каждый токен задействована вся сеть, а в MoE — только часть, через выбранных «экспертов». Из этого следует ключевое свойство: у MoE-модели два разных числа параметров — total, сколько их всего, и active, сколько реально считается на один токен.
Active определяет цену и скорость на один токен. На каждом токене провайдер считает ровно столько FLOPs, сколько занимает active-часть: 37B у V3.1, 17B у Maverick. Скорость генерации тоже привязана к active — чем больше параметров надо прогнать на один токен, тем медленнее ответ на том же железе. Total на эти две вещи не влияет.
Total определяет, сколько модель занимает в памяти и хостинге. Все 671B весов у V3.1 должны лежать в VRAM, даже если на каждом отдельном токене работают только 37B — ведь роутер заранее не знает, кого выберет на следующем. Поэтому хостить MoE-гиганта дороже, чем dense-модель того же active-размера: ты держишь в памяти весь зоопарк экспертов, а считаешь только восьмерых из них.
Total — это где живут знания, active — где крутится размышление. Каждый факт, который модель «помнит» (год смерти Пушкина, формула инсулина, идиома на португальском) статистически распределён между весами. Чем больше total, тем больше различимых паттернов влезает — рост сублинейный, но он есть: Llama 70B на factual-бенчмарках обходит Llama 8B примерно вдвое, при том что параметров в неё в 9 раз больше. Reasoning — то, как модель манипулирует этими знаниями в моменте — крутится в active compute на токен. Поэтому frontier-класс ушёл в 1T+ MoE: хочется storage-преимущества триллионной модели, не платя её compute-цену за каждый токен.
Если разворачиваешь локально — total говорит «влезет ли», active говорит «как быстро». Одна H100 80GB в BF16 комфортно держит модель до ~35B параметров (плюс KV-cache и активации). Llama 3.3 70B на одну карту лезет уже только в FP8 (~70 ГБ под веса) или 4-bit квантизации (~35 ГБ); полный BF16 требует двух H100 или одной H200 141GB. DeepSeek V3.1 (671B) и Kimi K2 (1T) дома — всегда multi-GPU плюс квантизация. Active при этом скажет про compute-нагрузку: V3.1 со своими 37B active даёт ту же работу на токен, что dense-модель на 37B — хотя на практике скорость генерации может быть ниже из-за роутер-overhead и того, что на каждом токене из памяти подтягивается свой набор экспертов.
И вот откуда новостные заголовки вроде «модель на 5 триллионов параметров» — это total, общее число параметров в сети. На каждый токен работают active, обычно в десятки раз меньше — и именно active определяет, сколько на этой модели стоит обработка одного токена.
Возьмём двух открытых представителей — DeepSeek V3.1 и Llama 4 Maverick:
MoE-архитектура · V3.1 и Maverick
MoE-гиганты на сотни миллиардов по compute и цене ведут себя как модели среднего размера
Total в сотни миллиардов звучит как флагманский монстр — но на каждый токен в MoE считаются десятки миллиардов параметров. V3.1 и Maverick — два примера одного паттерна
DeepSeek V3.1 · из 671 миллиарда на токен работают только 37
Llama 4 Maverick · из 400 миллиардов на токен работают только 17
Total — сколько параметров в модели всего. Active — сколько включается на каждый токен. В MoE это малая часть: у V3.1 — 37B из 671B, у Maverick — 17B из 400B. Десятикратный разрыв total/active типичен для всего класса.
По compute V3.1 и Maverick — оба между Llama 3.1 8B и Llama 3.1 70B
Compute считается по active: у Maverick — 2 × 17B = 34 миллиарда FLOPs на токен, у V3.1 — 2 × 37B = 74. Обе MoE-модели сидят между Llama 3.1 8B и Llama 3.1 70B по compute, хотя по total у них сотни миллиардов параметров. Для масштаба: dense-гигант Llama 3.1 405B делает 810 миллиардов FLOPs на токен — в 11 раз больше V3.1 и в 24 раза больше Maverick'а.
Вывод: счёт идёт за active, не за total
Цена MoE-модели идёт за реальный compute, а не за громкий ярлык total. V3.1 в прайсе — $0,27 input и $1,10 output за 1M токенов (снапшот конца 2024): по стоимости запроса сидит между Llama 3.1 8B и Llama 3.1 70B, а вовсе не как заявленный гигант на 671 миллиард. У Maverick на свежем провайдере (DeepInfra) input ещё дешевле — $0,15 за 1M, что ниже даже dense-8B: рынок прижимает цену MoE к active-параметрам, а не к total.
Отсюда вывод, который стоит запомнить: total — это маркетинг и капасити, а счёт выставляется по active. Когда в заголовке пишут «N триллионов параметров» — это почти всегда total. Реальный compute на токен на порядок меньше.
GPT-4, по утечкам 2023 года (SemiAnalysis), тоже MoE: около 1,8 триллиона параметров total и ~280 миллиардов active на токен — давняя и хорошо подтверждённая утечка. То есть флагман уже мерится в триллионах, а не миллиардах, но active у него всё равно «всего» 280B — в шесть раз меньше total. Про GPT-5 и Claude Opus вендоры архитектуру не раскрывают вовсе — тут уже не утечки, а экспертные догадки, что флагманы устроены похоже. А у Gemini это и не догадка: Google прямо называет его MoE в техотчёте. Точных рабочих цифр — сколько именно параметров active — всё равно не раскрывает никто. Логика, впрочем, та же: total ≠ active, и биллинг определяет active.
Output дороже input
До сих пор мы считали токен как токен. Но прайс любой модели делит их на два класса: input-токены — те, что ты отправил, — и output-токены, которые модель написала в ответ. И output почти всегда дороже.
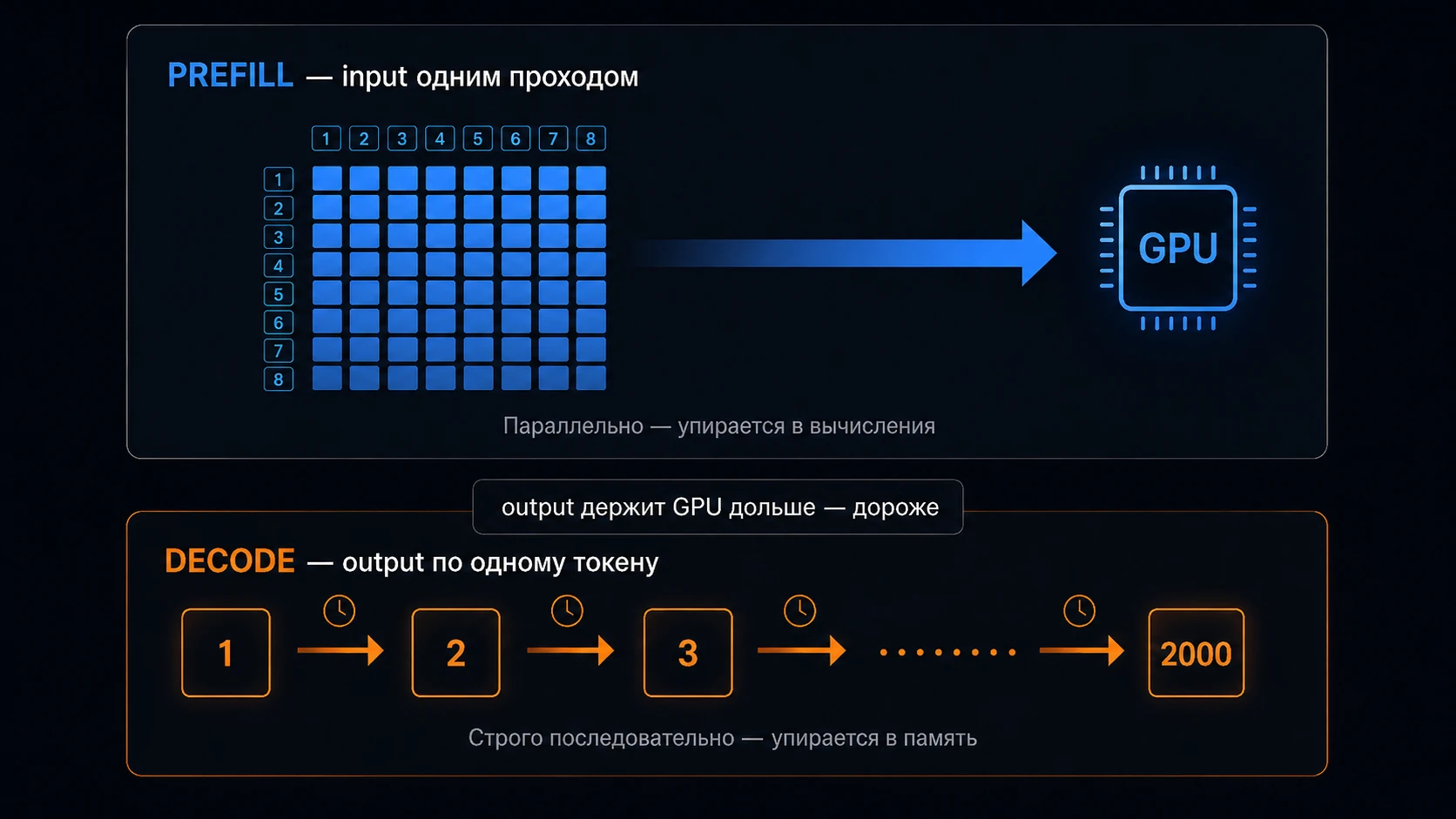
Input модель обрабатывает пачкой. Это называется prefill: ей дали весь промпт целиком, она прогнала его за один проход и построила внутреннее состояние. Prefill хорошо параллелится — это compute-bound фаза, она упирается в объём вычислений, а считать много и сразу GPU как раз умеет.
Output генерируется иначе — строго последовательно:
1-й токен → 2-й → 3-й → … → 2000-йНельзя получить 2000-й токен, пока не появился 1999-й — каждый следующий зависит от всех предыдущих. Эта фаза, генерация ответа, называется decode, и ведёт себя иначе, чем prefill. На каждый новый токен модель заново «перечитывает» из памяти GPU всё, что уже накопила, — и узкое место тут не скорость вычислений, а скорость доступа к памяти. На инженерном языке это и называют memory-bandwidth-bound. Если совсем просто — output держит GPU занятым дольше, хуже параллелится и потому стоит дороже.
На закрытых флагманах output обычно в 3–5 раз дороже input. У open-weight бывает иначе: некоторые провайдеры — например, Together — берут за input и output одну и ту же ставку.
Reasoning-токены — невидимый output
Когда у модели включён reasoning, она не пишет ответ сразу. Сначала она тратит токены на размышление: проверяет гипотезы, планирует, разбивает задачу на шаги. И только потом формулирует то, что ты увидишь. У Claude этот режим называют thinking, а настройка reasoning effort задаёт, сколько его.
Эти токены размышления в финальном тексте не видны. Но GPU их всё равно посчитал — а значит, они в счёте. Это невидимый output.
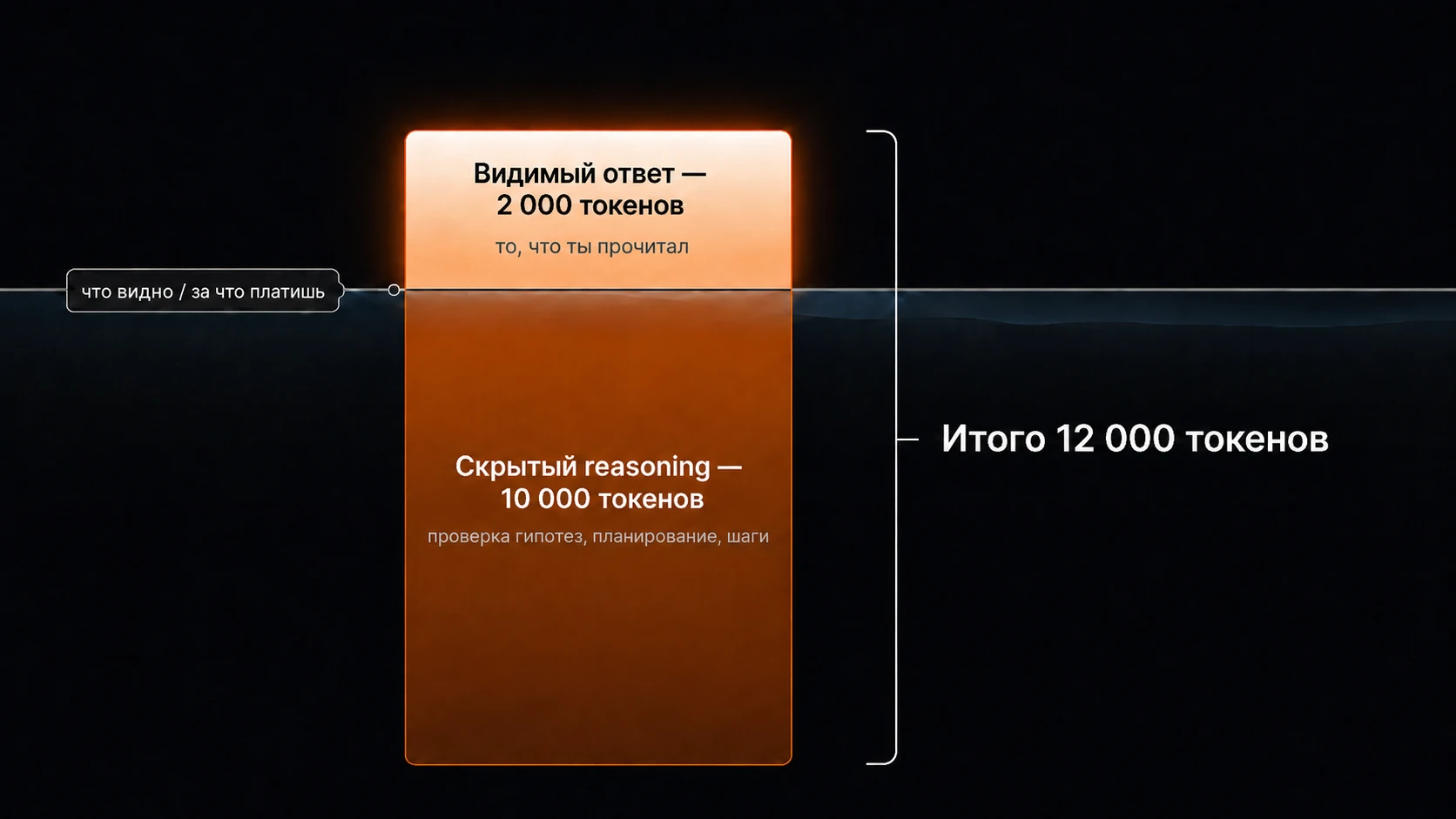
Как это выглядит на одном запросе:
- видимый ответ — 2 000 токенов
- внутреннее рассуждение — 10 000 токенов
- фактическая output-нагрузка — 12 000 токенов
Поэтому связка «дорогая модель + высокий effort» утяжеляет счёт не на 20%, а в разы
Ты платишь не только за текст, который увидел. Ты платишь за вычисления, которые помогли модели до него дойти.
Оговорка для нашего бенчмарка: у Llama полноценного reasoning-режима по-прежнему нет — это свойство frontier-флагманов, моделей переднего края, в которые дополнительно вложили RL — обучение с подкреплением — на размышление. Среди open-weight такой режим умеют немногие — DeepSeek (R1 и V4), Qwen 3.5/3.6 с togglable thinking mode, — но Llama 4 (Scout, Maverick) в их число не входит, а 2-триллионный Behemoth до сих пор не выпущен публично. Так что это слагаемое формулы мы переносим на закрытые модели по аналогии, а не считаем напрямую.
Большой контекст: дорого не только по токенам
Сразу проговорим развилку, иначе будет путаница. С большим контекстом есть два разных «дорого»:
- В прайсе ставка за токен обычно не зависит от длины контекстного окна — но не всегда: у Gemini Pro (и 2.5, и 3 Pro) запрос длиннее 200k токенов уходит на премиум-ставку, где input вдвое дороже, output — в полтора раза. У Flash-моделей этого порога нет — у них flat-ставка на любой длине. Claude от похожей наценки в версии 4.6 отказался
- Инфраструктурно длинный контекст тяжелее всегда — даже там, где цена за токен формально не меняется
Откуда берётся инфраструктурная тяжесть. Контекст — это не просто текст, лежащий рядом с моделью. Во время генерации модель держит KV-cache — рабочую память по уже обработанному контексту: чтобы на каждый новый токен не прогонять весь контекст заново, модель хранит промежуточный результат. Чем длиннее контекст, тем больше нужно этой памяти — и тем:
- больше VRAM (видеопамяти GPU) занято под KV-cache
- меньше запросов влезает на одну GPU — хуже батчинг
- выше латентность, и дороже обслуживать много пользователей разом
- сильнее вклад attention — того самого, что растёт быстрее длины контекста
Запрос на 5k токенов и запрос на 150k — инфраструктурно разные вещи, даже если цена input-токена одинаковая. Второй забивает больше GPU-памяти, хуже батчится и может попадать под отдельные лимиты или внутреннюю маршрутизацию — у провайдеров длинные контексты иногда идут через отдельную инфраструктуру со своими rate limits. «Засунуть весь проект в контекст» — это не бесплатная магия, а аренда большего куска GPU-памяти и времени.

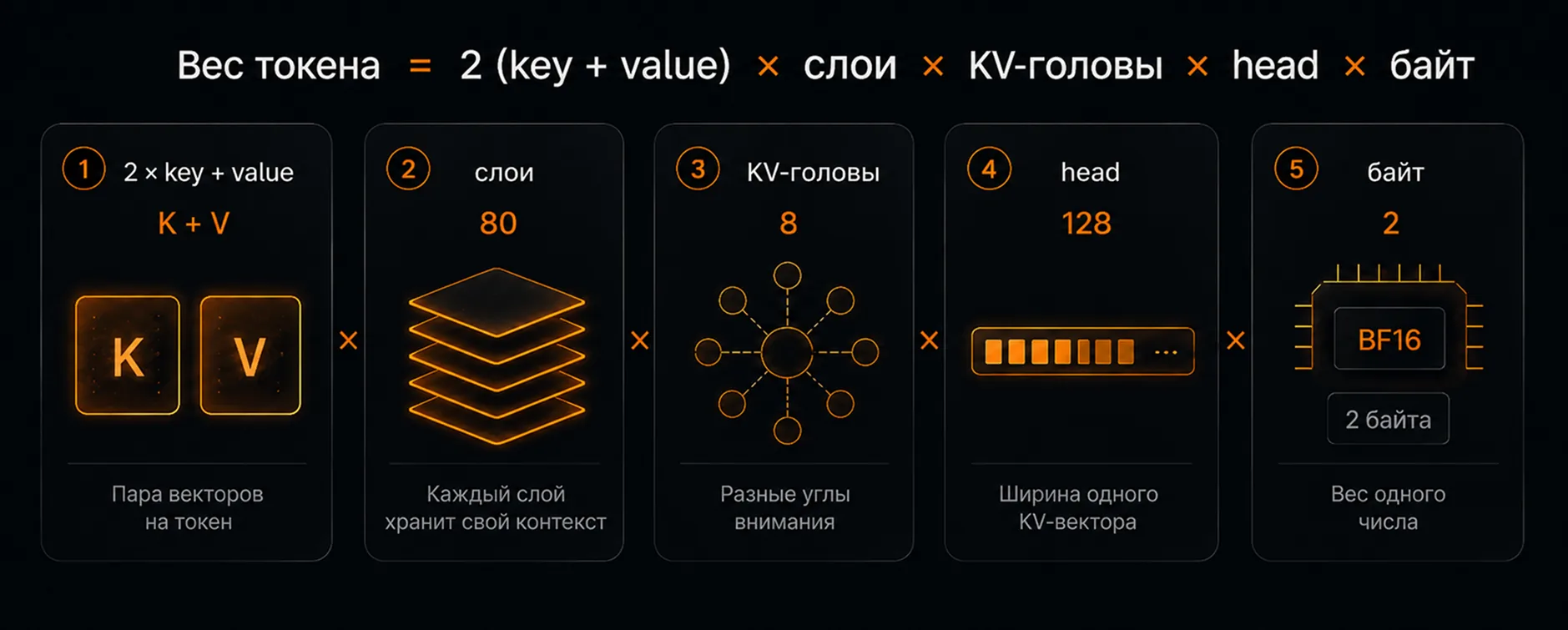
Главное про вес токена: он растёт с глубиной модели (число слоёв) и числом KV-голов, а от количества параметров почти не зависит. Поэтому вес одного токена в Llama 405B тяжелее одного токена Llama 70B всего в 1,6 раза, хотя по параметрам разница между моделями в 5,8 раза.
KV-cache · ↗ подробнее
Вес токена в KV-cache задаёт формула — и размер модели в неё не входит
Вес токена — произведение пяти множителей
| Модель | Слои | KV-голов | Вес токена (BF16) |
|---|---|---|---|
| Llama 3.1 8B | 32 | 8 | 128 КБ |
| Llama 3.1 70B | 80 | 8 | 320 КБ |
| Llama 3.1 405B | 126 | 8 | ~504 КБ |
| Llama 70B без GQA | 80 | 64 | 2,5 МБ |
Вес токена растёт с глубиной модели и числом KV-голов, но не с числом параметров: Llama 405B тяжелее 70B лишь примерно в 1,6 раза — 126 слоёв против 80, — хотя по параметрам разрыв в 5,8 раза. Последняя строка показывает работу GQA (Grouped Query Attention) — приём, при котором несколько query-голов делят общий KV-комплект. Без GQA 64 KV-головы вместо 8 раздули бы кэш в 8 раз — с 320 КБ до 2,5 МБ на токен.
Есть и обратная сторона — то, что счёт реально снижает. Это prompt caching. Если у тебя длинный системный промпт или контекстная шапка, которая повторяется от запроса к запросу, провайдер может её закэшировать. Закэшированный input у современных флагманов — Claude и GPT-5 — стоит в 10 раз дешевле обычного. Для агентов и долгих сессий, где одна и та же шапка летит в каждый запрос, это ощутимая экономия — иногда решающая.
Про Frontier модели
Frontier-класс дороже не по одной причине. Часть слагаемых мы уже разобрали поштучно на open-weight — их остаётся только сложить. Часть появляется именно у закрытых frontier-моделей.
Уже посчитано:
- больше active compute на каждый токен — главное слагаемое из главы про цену токена, у frontier-класса оно по максимуму
- больше reasoning budget — тот самый невидимый output, только потолок выше
Добавляет именно закрытость:
- меньше агрессивного батчинга — ради скорости отклика провайдер жертвует утилизацией GPU
- отдельная приоритетная latency lane — твой запрос не стоит в общей очереди; та самая задержка из главы про цену токена, только здесь её снимают деньгами
- SLA — контрактные гарантии по скорости и стабильности ответа, за которые провайдер отвечает деньгами
- дефицит — самых сильных GPU-кластеров физически мало, а спрос на них больше предложения
- монопольная маржа — у Llama цены прижаты конкуренцией провайдеров, у frontier-класса этого пресса нет
В отличие от Llama, размеры и архитектуру frontier-моделей мы не знаем — OpenAI и Anthropic их не публикуют. Поэтому раскладку выше стоит читать как обоснованную интерпретацию, а не как опубликованный факт. Какой именно фактор сколько весит — снаружи не видно.
Но общий вывод от этого не меняется: frontier-класс это вообще другой режим потребления вычислений — другой объём compute, другая очередь, другие гарантии.
Почему дорогая модель иногда реально умнее
Всё, что мы разбирали до сих пор, — про деньги. Но за тем же ценником скрывается вторая ось: дорогая модель часто и правда сильнее. «Умнее» в мире LLM — это сумма вполне конкретных вещей:
- знает и обобщает больше — даже при скромном количестве active параметров
- больше вычислений на обучение и дообучение — training и post-training
- лучше обучение с подкреплением (RL) на сложных задачах
- лучше работа с инструментами — tool use
- больше inference-time compute — больше внутренних попыток перед ответом
- лучше удержание цели на длинной цепочке шагов — критично для агентных сценариев, где их десятки
- меньше шанс потерять важное условие — критично уже для одного сложного one-shot промпта
Два последних пункта легко слить в один, но это разные вещи. Удержание цели — про долгую цепочку действий, где модель не должна забыть, куда шла. Потеря условия — про одну сложную задачу, где в промпте десять требований и нельзя проигнорировать восьмое.
Итого
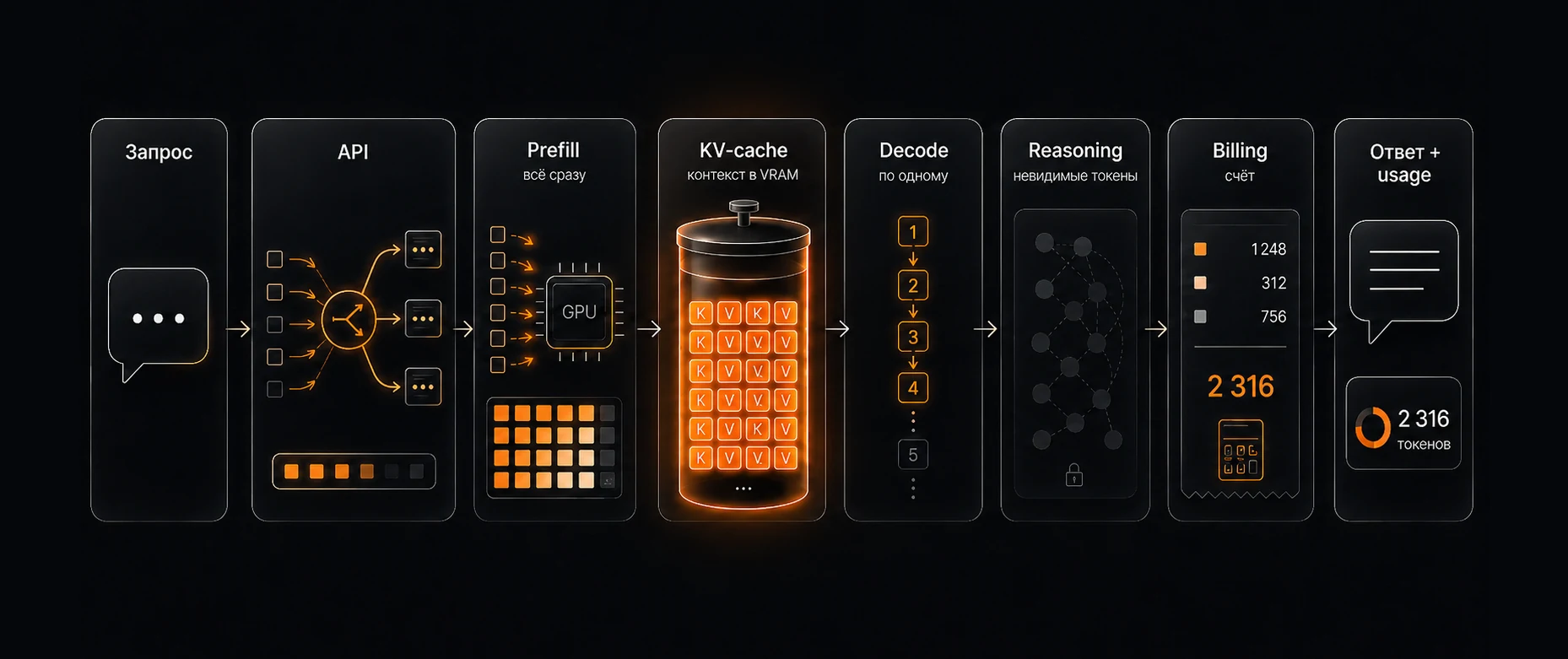
Дорогая модель дороже, потому что она тратит больше GPU-времени и GPU-памяти сразу в нескольких местах:
- дороже каждый токен — больше active compute, видно на Llama 8B → 70B → 405B
- total ≠ active — заголовки про «N триллионов параметров» обычно про total, а биллинг определяет active, видно на DeepSeek V3.1
- дороже output — он генерируется последовательно и упирается в память
- дороже reasoning — есть невидимые токены размышления
- дороже большой контекст — KV-cache забивает VRAM, а attention квадратичен
- дороже serving у закрытых frontier-моделей — меньше батчинга, приоритетная очередь, дефицит мощных кластеров, плюс монопольная маржа
Поэтому фраза «я просто выбрал самую умную модель» технически означает это:
я арендовал больше куска датацентра на каждый ответ
Что считает 5-часовое окно
Этот индикатор считает не количество сообщений, а compute, потраченный твоими запросами:
каждый токен весит столько, сколько даёт формула 2N × tokens, умноженная на коэффициент
текущей нагрузки серверов.
Поэтому одно сообщение в Opus с включённым reasoning и длинным контекстом может съесть процент так же, как двадцать коротких промптов в Sonnet.
Итого что именно влияет на потребление лимитов:
- active compute на токен — frontier-класс крутит больше параметров за один проход
- невидимые reasoning-токены — включённый thinking может стоить дороже видимого ответа
- длинный контекст — KV-cache забивает VRAM, attention квадратичен
- меньше батчинга у frontier-моделей — твой запрос идёт через приоритетную очередь с меньшей утилизацией GPU
- загрузка провайдера в моменте — в пиковые часы по планете GPU забиты одновременными запросами, и провайдер режет лимит жёстче, чтобы балансировать нагрузку
Все пять множителей — это те же главы, которые мы прошли, плюс оперативная нагрузка на провайдера. Всё сложено в один индикатор: «у тебя осталось 30%».
Процент в индикаторе — честный интеграл всей физики, которую мы разобрали.
Приложение: открытые модели в мае 2026
Сводный snapshot открытых LLM, которые в мае 2026 хостят inference-провайдеры — для тех, кто хочет посмотреть, как принципы из статьи раскладываются на конкретные модели и ценники. Снимок сделан 24 мая 2026 на основе данных artificialanalysis.ai и прайс-страниц провайдеров; колонка «Провайдер» в таблице показывает, чья цена попала в строку. Из 17 моделей пять появились с марта по апрель 2026: Nemotron 3 Super (NVIDIA), GLM-5.1 (Z.ai), Kimi K2.6 (Moonshot), MiMo V2.5 Pro (Xiaomi) и DeepSeek V4 Pro. Open-weight frontier переехал в класс «1T+ MoE с ~3% активации», и это видно в трёх чартах ниже: active, total и цены за 1M токенов.
Open-weight · 17 моделей · 24 мая 2026
Active на токен · 17 моделей по убыванию
Длина бара — сколько миллиардов параметров реально включается на каждый токен. Шкала общая (максимум — Llama 3.3 70B). Total справа — для понимания, насколько модель «больше» своей рабочей части. Видно, как 1T+ MoE — Kimi K2.6, MiMo V2.5 Pro, DeepSeek V4 Pro — уживаются в средней зоне active (32–49B), хотя по total они в разы больше.
Сортировка по active параметрам · от 70B до 5,1B
Бар показывает active — то, что реально активируется на каждом токене и определяет FLOPs одного прохода. Total в подписи — общий размер модели: у dense он совпадает с active, у MoE — в разы больше. Шкала бара общая для всех 17 строк, максимум — 70B (Llama 3.3 70B).
Что active определяет. Цену токена у провайдера: он считает по формуле FLOPs ≈ 2N · active и выставляет ценник по этой работе. Скорость генерации: чем больше active, тем медленнее ответ на том же железе. Total на эти две вещи не влияет.
Если разворачиваешь локально: active — это compute-нагрузка на GPU при каждом проходе, то есть latency на токен.
Сортировка по total параметрам · от 1600B до 8B
Тот же набор моделей, но сортировка по total параметрам. Бар показывает Total — общий размер модели; active в подписи приглушён, потому что здесь главное Total. Шкала общая для всех 17 строк, максимум — 1600B (DeepSeek V4 Pro). Видно, как 1T+ MoE доминируют по размеру, и как dense-модели в этом масштабе превращаются в миниатюры.
Что total определяет. Размер файла модели и требуемый объём VRAM: всю модель нужно держать в памяти GPU. Стоимость серверной инфраструктуры у провайдера тоже растёт с total. Active на это не влияет.
Если разворачиваешь локально: total — это первый вопрос: «влезет ли модель в мой GPU?». Одна H100 80GB в BF16 держит модель до ~35B (например, dense-Llama 3.1 8B или DeepSeek V3.1 в active-режиме); 70B-модель влезает уже только в FP8 (~70 ГБ под веса) или 4-bit квантизации (~35 ГБ). Kimi K2 (1T) дома даже в 4-bit требует ~500 ГБ — это multi-GPU кластер минимум на 7 карт.
Цены за 1M токенов · input vs output, сортировка по output
Цена в долларах за 1 миллион токенов.
Что определяет input/output цены. Input — это prefill-стадия: провайдер прогоняет весь промпт за один параллельный pass через GPU, эффективно утилизируя compute. Output — decode: каждый токен генерится последовательно, упираясь в memory bandwidth.
Поэтому у GLM-5.1 output дороже input в 3,1 раза, у Kimi K2.6 — в 4,2, у DeepSeek V3.1 — в 3,8. У dense Llama 3.x и Gemma разрыв скромнее (2–3×), потому что compute и memory bandwidth балансируют друг друга проще.
| Модель | Производитель | Архитектура | Total, B | Active, B | Контекст | Input $/1M | Output $/1M | Провайдер |
|---|---|---|---|---|---|---|---|---|
| Llama 3.3 70B Instruct | Meta | dense | 70 | 70 | 128k | $0,10 | $0,32 | DeepInfra Turbo |
| DeepSeek V4 Pro | DeepSeek | MoE | 1600 | 49 | 1M | $0,43 | $0,87 | DeepSeek API |
| MiMo V2.5 Pro | Xiaomi | MoE | 1023 | 42 | 1M | $1,00 | $3,00 | Xiaomi API |
| Mistral Large 3 | Mistral AI | MoE | 675 | 41 | 256k | $0,50 | $1,50 | Mistral AI |
| GLM-5.1 | Z.ai (Zhipu) | MoE | 744 | 40 | 200k | $1,40 | $4,40 | Together AI |
| DeepSeek V3.1 | DeepSeek | MoE | 671 | 37 | 128k | $0,21 | $0,79 | DeepInfra (FP4) |
| Kimi K2.6 | Moonshot AI | MoE | 1000 | 32 | 256k | $0,95 | $4,00 | MoonshotAI |
| Kimi K2 Instruct | Moonshot AI | MoE | 1000 | 32 | 256k | $0,50 | $2,00 | DeepInfra |
| GLM-4.6 | Z.ai (Zhipu) | MoE | 357 | 32 | 200k | $0,60 | $2,20 | Together AI |
| Gemma 3 27B Instruct | dense | 27 | 27 | 128k | $0,08 | $0,16 | DeepInfra | |
| Qwen3 235B A22B | Alibaba | MoE | 235 | 22 | 256k | $0,20 | $0,60 | Together AI |
| Llama 4 Maverick 17B 128E | Meta | MoE | 402 | 17 | 1M | $0,15 | $0,60 | DeepInfra |
| Llama 4 Scout 17B 16E | Meta | MoE | 109 | 17 | 10M | $0,08 | $0,30 | DeepInfra |
| Nemotron 3 Super 120B A12B | NVIDIA | hybrid MoE | 120 | 12 | 1M | $0,30 | $0,75 | Baseten |
| MiniMax M2 | MiniMax | MoE | 230 | 10 | 205k | $0,30 | $1,20 | MiniMax API |
| Llama 3.1 8B Instruct | Meta | dense | 8 | 8 | 128k | $0,02 | $0,05 | DeepInfra |
| gpt-oss-120B | OpenAI | MoE | 117 | 5,1 | 131k | $0,15 | $0,60 | Together AI |
Главное, что видно в Chart-2 — open-weight frontier переехал в класс «1T+ MoE». Четыре модели имеют 1 триллион и больше total: DeepSeek V4 Pro (1,6T), MiMo V2.5 Pro (1,02T), Kimi K2.6 (1T), Kimi K2 (1T). У всех active в диапазоне 32–49B — то есть на каждом токене реально работает 2–5% от общего размера модели. Это «3% активации» — новая норма frontier-класса 2026 года; ещё полгода назад единственным представителем был Kimi K2.
MoE-экономия отражается прямо в ценнике. Kimi K2 Instruct ($0,50 / $2,00) стоит как dense-модель класса 30B, при том что под капотом 1 триллион параметров. Платите вы только за active: именно через них проходит каждый токен и считаются FLOPs. Total влияет на VRAM и стоимость хостинга у провайдера, но не на цену токена. Самый яркий случай — gpt-oss-120B: при 117B total и всего 5,1B active цена $0,15 / $0,60 ниже, чем у dense Llama 3.3 70B по output. Обратный пример — Kimi K2.6 ($0,95 / $4,00): та же 1T/32B-архитектура, что и у K2, но надбавка за reasoning почти удваивает цену.
Разрыв input vs output подтверждает теорию prefill/decode: у DeepSeek V3.1 output дороже input в 3,8 раза, у GLM-4.6 — в 3,7, у Kimi K2 — ровно в 4 (после переоценки в марте 2026). Причина та же, что и в основном разборе: prefill параллелизуется через всю длину промпта, decode идёт по одному токену и упирается в memory bandwidth. Типовой запрос (1000 input + 500 output токенов) на Llama 3.3 70B стоит $0,00026; на DeepSeek V3.1 — $0,0006 (в 2,3 раза дороже при в 9 раз большем total); на Kimi K2.6 — $0,003 (в 11,5 раз дороже Llama 3.3 70B, но всё равно в 4–10 раз дешевле GPT-5 и Claude Opus на сопоставимой задаче).
Геополитический сдвиг — ещё один паттерн, который сложно не заметить. В таблице 17 моделей от 11 лабораторий. Среди топ-7 по active (DeepSeek V4 Pro, MiMo, Mistral Large 3, GLM-5.1, V3.1, K2.6, K2) — пять китайских лабораторий: DeepSeek, Xiaomi, Z.ai, Moonshot. На artificialanalysis.ai в мае 2026 топ-10 open-weight по Intelligence Index — все китайские; единственные не-китайские модели в первой двадцатке — gpt-oss-120B (OpenAI), Nemotron 3 Super (NVIDIA), Gemma 4 31B (Google) и Mistral Medium 3.5. Полгода назад расклад был ещё близок к паритету.
Hybrid attention — следующий виток. Nemotron 3 Super 120B A12B — единственный «не-чисто-MoE» в таблице: hybrid Mamba-Transformer + NVIDIA-кастомный LatentMoE + multi-token prediction, обучен в NVFP4. NVIDIA позиционирует его как 2,2× throughput gpt-oss-120B при сопоставимом качестве. Это сигнал: после того как MoE стало стандартом, следующий виток инноваций уходит в attention-механизмы — sparse, hybrid, Mamba. У DeepSeek V4 и GLM-5.1 тоже заявлены кастомные attention, но конкретные параметры лаборатории пока не раскрывают.
Источники
Важная оговорка о числах. Все цены в статье — датированный снапшот на 2026 год;
рынок inference двигается быстро, и через полгода ставки могут быть другими. Оценка
FLOPs/token ≈ 2N — общеизвестная аппроксимация для dense-трансформера,
а не точная формула. Раскладка факторов frontier-класса — обоснованная интерпретация,
а не опубликованные данные провайдеров.
-
Together AI — Pricing
Публичный прайс провайдера. Источник цен на Llama 3.1 (8B / 70B / 405B), на которых построена таблица в разделе про цену токена
-
DeepSeek-V3 Technical
Report
Технический отчёт DeepSeek с архитектурой модели: MoE, 671B параметров total и 37B активных на токен. Основа раздела про total ≠ active
-
OpenAI — Prompt Caching
Документация про кэширование промптов: закэшированный input дешевле обычного. Фон для врезки о prompt caching
-
Anthropic — Prompt Caching
То же со стороны Anthropic: как устроено кэширование и насколько оно снижает стоимость повторяющегося контекста