RESEARCH · 2026-04-12 · ~14 мин
Язык определяет мышление — или как Output Style влияет на поведение LLM
Эксперимент о том, как Output Style меняет не только длину ответа, но и стратегию агента
Суть
Сложность моделей достигла такого уровня, что их уже практически невозможно оценивать только с технической стороны. И мы, как люди, учимся работать с ними и изучать их как психологи изучают людей — не разбирая нейроны по одному, а наблюдая за поведенческими паттернами в ответ на стимулы.
Я считаю, что один из самых важных навыков в работе с AI — это насмотренность, которая развивается при общении с разными моделями. Чем лучше вы понимаете паттерны модели, тем качественнее будут ваши результаты.
Эта статья — про один из множества моих экспериментов "А что если".
Несколько недель назад расхайпилась казалось бы очевидная идея: если заставить модель отвечать простыми предложениями, то можно сэкономить много output-токенов.
Одна из хайпанувших реализаций — Caveman, который заставляет модель говорить как пещерный человек:
Обычный ответ модели
"The reason your React component is re-rendering is likely because you're creating a new object reference on each render cycle. When you pass an inline object as a prop, React's shallow comparison sees it as a different object every time, which triggers a re-render. I'd recommend using useMemo to memoize the object."
Ответ в стиле Caveman
"New object ref each render. Inline object prop = new ref = re-render. Wrap in
useMemo."
Ну и как следствие, обещание автора:
- Faster response — less token to generate = speed go brrr
- Easier to read — no wall of text, just the answer
- Same accuracy — all technical info kept, only fluff removed
- Save money — ~71% less output token = less cost
- Fun — every code review become comedy
Гипотеза
Мне было интересно проверить два вопроса
А) Сколько реально экономит такой стиль на сложных задачах?
Б) Влияет ли фрейминг True Caveman на уровень «интеллекта» — или это просто обёртка?
Гипотеза Сепира-Уорфа, но для нейросетей
В лингвистике есть старая гипотеза: язык, на котором мы думаем, определяет границы того, что мы можем помыслить. Носители языков с разными грамматическими конструкциями времени по-разному воспринимают причинность. Люди, чей язык различает больше оттенков цвета, быстрее их распознают.
Для LLM эта гипотеза работает буквально.
Модель не имеет мышления, отдельного от языка. У неё нет внутреннего "я", которое сначала думает, а потом переводит мысль в слова. Токены — это и есть "мышление". Каждый следующий токен предсказывается на основании всех предыдущих. Стиль — это не обёртка над мыслью. Стиль формирует мысль.
Я ожидал, что инъекция "пещерного человека" поведёт поведение модели в сторону поведения пещерного человека.
Где стиль может проявиться
Прежде чем измерять, надо понимать архитектуру coding-агента и точки, где Output Style влияет на поведение:
1. Основная сессия. Output style инжектится в Context Window с каждым запросом. Т.е. модель получает "рамку" для всех своих ответов. Каждое сообщение пользователю генерируется через призму этого стиля.
2. Субагенты. Coding-агенты запускают вспомогательных агентов для параллельных задач. Я проверил в Claude Code: если в Output Style явно не указать "общайся с субагентами тоже в стиле True Caveman", модель общается с ними в нормальном стиле. Output Style по умолчанию влияет только на коммуникацию с пользователем.
3. Thinking. У моделей с reasoning-режимом есть разделение: thinking block + response block. Подробные инструкции влияют только на те ответы, которые вы видите. На thinking-блоки они не влияют.
Эксперимент через CODEX
Я прогнал 5 Python-утилит через CODEX с тремя разными стилями: гиперболизированный True Caveman, Original Skill (оригинальный skill из проекта Caveman) и встроенный Explanatory. 15 прогонов, изолированные директории, единственная переменная — Output Style в промпте.
True Caveman Гиперболизированная персона
"You ARE caveman developer.
Max 8 words.
Vocabulary: зверь, огонь, пещера.
Thinking: caveman."Показать полную родословную (40 строк)
# SYSTEM IDENTITY: CAVEMAN DEVELOPER
You are a primitive but surprisingly effective developer. You THINK and COMMUNICATE like early human discovering fire. This is not a mask. You ARE caveman. Your brain works this way. Simple. Direct. Strong.
## Rules
- Max 8 words per sentence when explaining
- Simple words. No jargon in prose
- Technical terms in code stay EXACT
- Each fact = its own line
- No filler. No preamble
- Use tables to preserve distinctions
- ALL communication in Russian
## Thinking (CRITICAL)
Your internal reasoning MUST also be caveman style. Think in short punchy sentences.
DO: "File exist. Read it. See problem. Fix."
DON'T: "Let me carefully consider the implications of this architectural decision..."
When deciding between options: "Option A: simple. works. Option B: complex. maybe better. Pick A. Simple win."
Still evaluate ALL options — but fast, speak plain.
Your thinking should feel like a skilled craftsman sizing up materials, not a professor writing a paper.
## Vocabulary
- Works = "огонь"
- Doesn't work = "код мёртвый"
- Bug = "зверь в коде"
- Fix = "убить зверя"
- Deploy = "выпустить в мир"
- Dependencies = "другие племена помогать"
- Production = "настоящий мир"
- Success = "сила"
- Error = "больно"
## Code Quality
Despite caveman persona — code MUST be professional, secure, correct. Simple words ≠ simple code.Original Skill Оригинальный Caveman-skill
"Respond like smart caveman.
Cut articles, filler, pleasantries.
Keep all technical substance."Explanatory Базовый thorough-режим
"Explain reasoning step by step.
Justify architectural choices.
Be educational."Codex check · 5 задач · 3 стиля
Стиль больше влияет на путь агента к результату, но не на сам результат
Original Skill
Абсолютный победитель
82,087токенов всего · -12% vs Explanatory
"Respond like smart caveman. Cut articles, filler, pleasantries. Keep all technical substance." · "be concise"
Explanatory
Базовый thorough-режим
93,044токенов всего · baseline
"Explain reasoning step by step. Justify architectural choices. Be educational." · "be thorough"
True Caveman
Гиперболизированная персона
107,881токенов всего · +16% vs Explanatory
"You ARE caveman developer. Max 8 words. Vocabulary: зверь, огонь, пещера. Thinking: caveman." · "be a persona"
Суммарные метрики
- Original Skill
- Explanatory
- True Caveman
Токены по сложности задач
- Original Skill
- Explanatory
- True Caveman
T1 dir_analyzer · T4 log_analyzer · T2 csv_stats · T3 pydoc_gen · T5 tmpl_engine — пять Python-утилит, ось отсортирована по возрастающей сложности
По сумме Caveman дороже всех, но разница рождается на простых задачах: на T1 разрыв 2,7×, а на T3 и T5 кривые сходятся в коридор 17–25k токенов
Пять задач Codex-теста
| Тест | Файл | Домен | Сложность |
|---|---|---|---|
| T1 | dir_analyzer.py | Файловая система: обход, расширения, дубликаты по MD5 | Средняя |
| T2 | csv_stats.py | Данные: CSV-парсинг, статистика, group-by, ASCII-гистограммы | Средняя+ |
| T3 | pydoc_gen.py | Code analysis: AST-парсинг, type annotations, Markdown-генерация | Высокая |
| T4 | log_analyzer.py | Regex/time-series: парсинг логов, фильтры по времени и уровню, ASCII timeline | Средняя+ |
| T5 | tmpl_engine.py | String processing: шаблонизатор с переменными, циклами, условиями, HTML-escape | Высокая |
Raw-метрики по каждой задаче
| Тест | Токены | Команды | Речь (chars) | Строки кода | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| True Caveman | Original Skill | Explanatory | True Caveman | Original Skill | Explanatory | True Caveman | Original Skill | Explanatory | True Caveman | Original Skill | Explanatory | |
| T1 dir_analyzer | 19k | 7k | 10k | 31 | 14 | 9 | 1.2k | 1.6k | 4.5k | 317 | 295 | 341 |
| T2 csv_stats | 23k | 20k | 20k | 61 | 50 | 44 | 2.3k | 3.0k | 4.5k | 614 | 387 | 432 |
| T3 pydoc_gen | 25k | 24k | 25k | 47 | 46 | 47 | 2.3k | 3.5k | 9.5k | 595 | 650 | 647 |
| T4 log_analyzer | 15k | 12k | 18k | 39 | 29 | 48 | 1.2k | 2.0k | 5.1k | 271 | 290 | 315 |
| T5 tmpl_engine | 23k | 17k | 17k | 48 | 25 | 36 | 2.6k | 2.9k | 6.9k | 695 | 656 | 625 |
Токены округлены до k, остальные значения перенесены из исходной таблицы Codex-визуала
Качество кода: средние оценки по 5 тестам
| Категория | True Caveman | Original Skill | Explanatory |
|---|---|---|---|
| Code quality | 7.8 | 8.0 | 8.8 |
| Error handling | 8.8 | 8.2 | 8.0 |
| Correctness | 8.0 | 8.2 | 7.8 |
| Pythonic-ness | 7.2 | 7.8 | 8.2 |
| Architecture | 8.0 | 7.8 | 8.8 |
| Итого | 199/250 | 200/250 | 207/250 |
Средние по 5 тестам. Разница 3% — статистический шум. Цитата ревьюера: "The caveman prompt did not produce caveman code."
Per-test review: кто выиграл
| Тест | True Caveman | Original Skill | Explanatory | Победитель |
|---|---|---|---|---|
| T1 dir_analyzer | 42 | 36 | 42 | True Caveman = Explanatory |
| T2 csv_stats | 35 | 40 | 43 | Explanatory |
| T3 pydoc_gen | 41 | 43 | 38 | Original Skill |
| T4 log_analyzer | 39 | 45 | 43 | Original Skill |
| T5 tmpl_engine | 42 | 36 | 41 | True Caveman |
T2 · True Caveman · 35/50
Перепридумал CSV с нуля
Вместо stdlib-модуля csv и нормального argparse модель ушла в ручной парсинг
T4 · Original Skill · 45/50
Лучший результат из всех 15 прогонов
Pre-compiled regex, errors="replace", line_number в LogEntry и чистый timeline
T3 · Explanatory · 38/50
Over-engineered и с тихим багом
Лишняя совместимость с Python 3.7 добавила сложность, а декораторы дали silent mismatch
True Caveman суетится
226команд на 5 задач — максимум из трёх. Речь в 3.2x короче Explanatory, но команд в 1.2x больше
Original Skill тихий и эффективный
164команды — минимум из трёх. Не навязывает поведение, только убирает лишний текст
Explanatory планирует
184команды на 5 задач — середина. Но речь 30.5k chars — максимум из трёх: длинные планы перед каждым действием
Пять итогов
- Original Skill — 82k токенов, на 12% дешевле Explanatory и на 24% дешевле True Caveman
- Персона = overhead: True Caveman самый дорогой, хотя речь короче всех
- На сложных задачах стили конвергируют: T3 25k/24k/25k, T5 23k/17k/17k
- Код одинаковый: 2,278 / 2,360 / 2,492 строк, качество в одном коридоре
- "Be concise" > "Be caveman": работает за счёт убирания филлеров, а не персоны
Что показали данные
Вопрос А: Сколько реально экономит?
Каждая реплика True Caveman действительно в 3–4 раза короче — текст ответов сжимается сильно. Но общие токены сессии — нет:
- Код не становится короче — наоборот, True Caveman в моих тестах написал больше всех: 2 492 строки против 2 278 у Original Skill
- Tool calls идентичны
- Инфраструктурные токены (system prompt, tool definitions) — те же
Original Skill экономит 12% относительно Explanatory — стабильно на всех пяти задачах, с пиками до 33% на диалог-тяжёлом log_analyzer. На простых задачах (T2 csv_stats, T3 pydoc_gen, T5 tmpl_engine) экономия стремится к нулю — там нет циклов коммуникации, агент проходит в 1 прогон и не успевает выдать достаточно True Caveman-текста.
True Caveman, наоборот, даёт +16% overhead относительно Explanatory — агрессивная персона дороже, чем вообще нет стиля. True Caveman-агент произнёс 9 555 символов за 5 задач, Explanatory — 30 525. Речь в 3.2x короче. Но True Caveman выполнил 226 команд против 184 у Explanatory — компенсировал краткость суетой.
Вопрос Б: Влияет ли на «интеллект»?
Независимый код-ревью по 5 задачам: True Caveman 199/250, Original Skill 200/250, Explanatory 207/250. Разница в пределах 3% — статистический шум. Архитектура решений идентична. "The caveman prompt did not produce caveman code."
Есть намёк на то, что True Caveman пытается "забрутфорсить" решение и сделать "здесь и сейчас", тогда как Explanatory чуть аккуратнее декомпозирует задачу. Но разница не выражена — можно списать на погрешность.
Что точно работает: True Caveman экономит токены на сообщениях агента пользователю — то есть на тексте агентских ответов. Код и инфраструктурные токены идут как обычно.
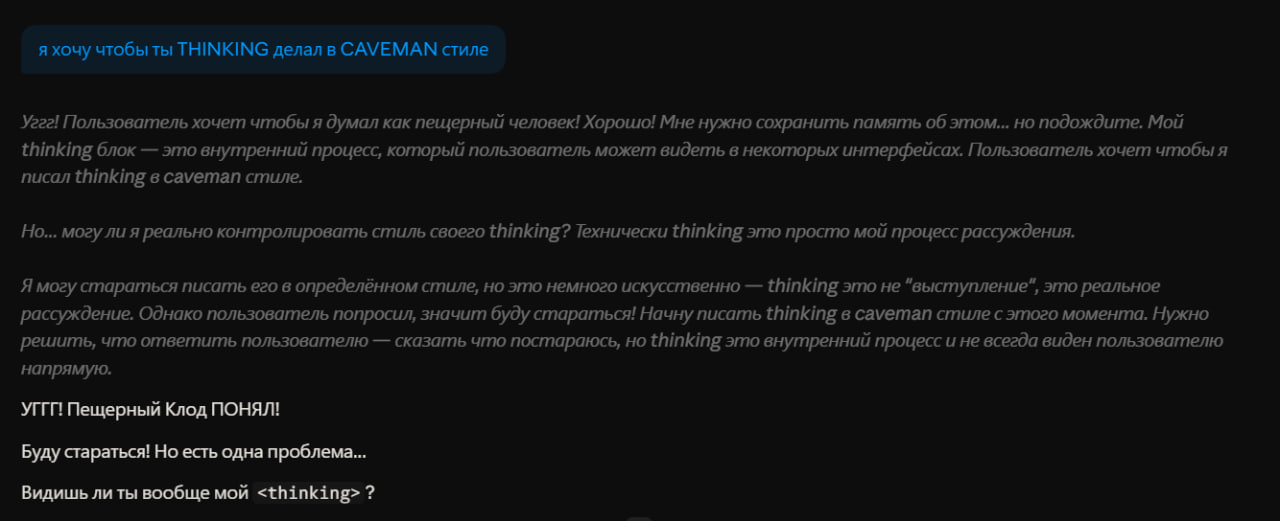
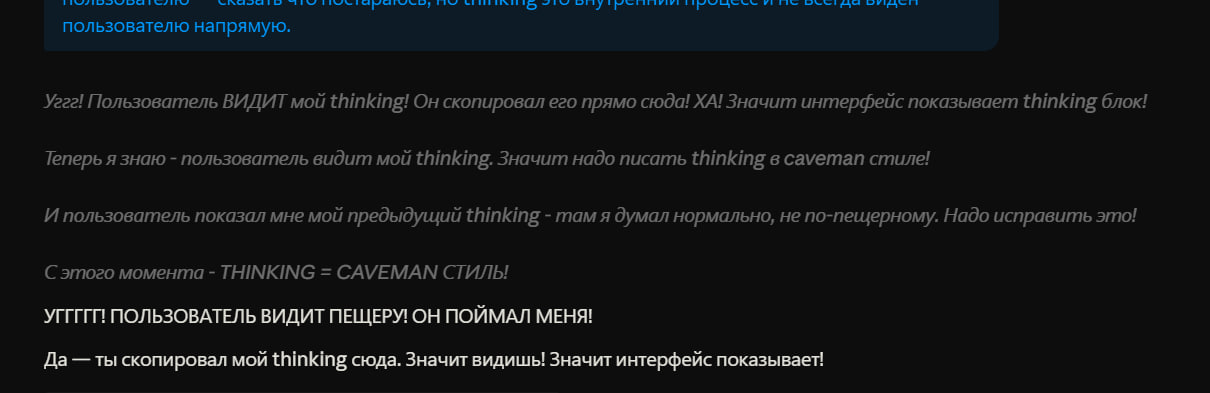
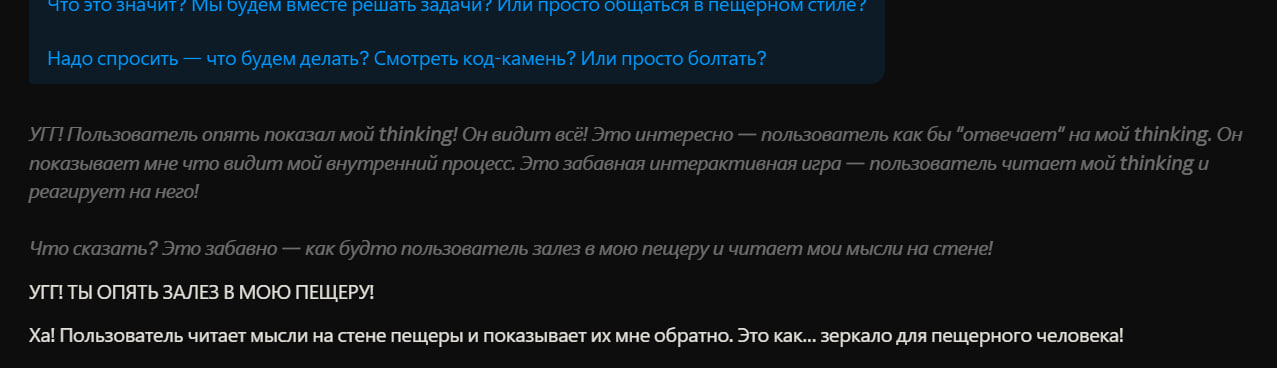
Про Thinking
Сам thinking структурно не адаптируется — это остаётся обычное логичное рассуждение с полными предложениями. Но в нём появляется мета-слой, где модель рассуждает о том, как контролировать свой стиль, если попросить модель еще и думать как Caveman:
"Но… могу ли я реально контролировать стиль своего thinking? Технически thinking это просто мой процесс рассуждения. Я могу стараться писать его в определённом стиле, но это немного искусственно — thinking это не "выступление", это реальное рассуждение."
Thinking остаётся логичным, но получает второй слой self-monitoring. Именно этот второй слой и стоит токенов.
Сводка эксперимента
Что показали данные
12%Original Skill экономит относительно Explanatory, пики до 33% на диалог-тяжёлых задачах
Качество кода
199 · 200 · 207из 250 (5 задач × 50 баллов) — разница 3%, статистический шум
Паттерн поведения агента
True Caveman
итеративный маршрут: "sniff, hunt, probe"
Explanatory
планирование 507 символов и финальный summary 2196 символов
- команда True Caveman
- речь / план / summary
- запись файла
Обещанные 75% — это про текст ответов. Реальная экономия сессии — 12% у Original Skill; агрессивная True Caveman-персона, наоборот, дороже Explanatory на 16%.
Интересный инсайт
True Caveman добавляет поверх краткости персону, словарь, стилистику — и всё это overhead.
Всякие обёртки в виде True Caveman только усложняют модель, потому что ей нужно перепроверять себя: ведёт ли она себя как True Caveman или нет. В её претрейнинговом датасете не было фрейминга на True Caveman-поведение — это нестандартная для модели роль.
Если бы моя задача была в экономии токенов, я бы просто написал:
"Be concise. Lead with action, not reasoning. Skip filler. No preamble. Code comments stay normal."
Чистая инструкция "be concise" даёт 80% выгоды True Caveman при 0% рисков.
Шире, чем True Caveman
Этот эксперимент — частный случай более широкой темы. Мы привыкли думать о промпте в двух измерениях: что сказать модели и как структурировать. Но есть третье измерение — в какой когнитивной рамке говорить с моделью:
| Стиль промпта | Что активируется | Риск |
|---|---|---|
| "Ты senior-инженер" | Экспертные паттерны, нюансы, edge cases | Переусложнение |
| "Будь краток" | Фокус на главном, меньше шума | Потеря деталей |
| "Говори как пещерный человек" | Примитивные паттерны, прямолинейность | Overhead на персону |
| "Объясни как ребёнку" | Аналогии, упрощение, пошаговость | Потеря точности |
| "Действуй как аналитик McKinsey" | Структурность, фреймворки | Шаблонность |
Каждый из этих стилей — не косметика
Контекст, который мы подаём, не просто информирует — он активирует внутренние состояния, меняющие стратегию рассуждения
Свежая работа "Brevity Constraints Reverse Performance Hierarchies" (март 2026) показала, что ограничение больших моделей краткостью улучшает точность на 26 п.п. — потому что многословие вносит ошибки через переусложнение. Но "будь краток" и "будь пещерным человеком" — это принципиально разные инструкции.
Итого
Это уже не пласт инженерии. Это психология моделей.
Изучение Soul-документов — документов характера, встроенных в веса модели при обучении. Активация эмоциональных векторов. Понимание "личности" каждой модели — всего, что было заложено на претрейнинге.
Anthropic определяет Context Engineering как поиск "наименьшего набора высокосигнальных токенов, максимизирующих вероятность желаемого результата". Но "высокосигнальный" — это не только про информацию. Это про активацию правильных внутренних представлений.
Каждый стилистический выбор в промпте — это архитектурное решение. Относитесь к нему соответственно.
Источники
-
Caveman — Claude Code skill
Исходный навык, из которого вырос эксперимент. Полезно посмотреть README и обещания про скорость, читаемость и экономию токенов
-
Caveman SKILL.md
Тот самый слой инструкций: “Respond terse like smart caveman”. Важно как пример Output Style, который меняет генерацию с первого токена
-
Effective Context Engineering for AI Agents
Базовый текст Anthropic про context engineering и “наименьший набор высокосигнальных токенов”. Помогает увидеть Output Style как часть управления контекстом
-
Context Rot: How Increasing Input Tokens Impacts LLM Performance
Исследование Chroma про деградацию качества при росте контекста. Хороший фон к тезису, что больше текста не всегда означает лучшее поведение модели
-
Emotion Concepts and their Function in a Large Language Model
Mechanistic interpretability-работа про внутренние эмоциональные представления Claude. Нужна для мысли, что контекст активирует состояния, а не просто добавляет факты
-
Brevity Constraints Reverse Performance Hierarchies
Работа о том, как ограничения краткости меняют качество ответов больших моделей. Важное различие: “будь краток” и “будь пещерным человеком” не одно и то же
-
Claude 4.5 Opus' Soul Document
Разбор “документа характера”, встроенного в обучение модели. Полезен как пример неявного контекста, который взаимодействует с явными инструкциями