ГЛАВА 3 ИЗ 12 · ~15 мин
Как работает ChatGPT

После небольших вводных в ИИ давайте я расскажу о том, как на самом деле работают нейросети.
Это нужно, чтобы избежать иллюзий и не идеализировать ответы, полученные от ИИ
📚 Что внутри главы
- Что такое ChatGPT на самом деле
- Как устроено обучение нейросети
- Что такое токены и как работает токенизация
- Контекстное окно: как модель "помнит" информацию
- Проблемы длинных контекстных окон
- Как LLM обрабатывает числа
- Пять рабочих сценариев для решения проблем при общении с ChatGPT 🔥
Что такое ChatGPT на самом деле?
Когда вы общаетесь с ChatGPT, вы взаимодействуете не с мыслящим искусственным интеллектом, а со статистической моделью
Модель же в нашем случае — это математический механизм, который учится на текстах, чтобы предсказывать наиболее вероятные продолжения новых текстов.
Эта модель обучена предсказывать наиболее вероятный ответ на основе огромного объёма данных, размеченных людьми по специальным инструкциям от компаний вроде OpenAI, которые и создают ChatGPT
Как обучают большие языковые модели по типу GPT
- Для начала нам нужно найти огромное количество сырого текста: книги, статьи, интернет-форумы, коды программ и так далее.
- Затем этот текст очищают и превращают в структурированный массив данных
- После этого текст конвертируется в биты — единицы цифровой информации
- В этом массиве информации модель начинает искать паттерны и повторяющиеся закономерности
- И группируем самые частые паттерны в токены, с которыми модель и будет работать в дальнейшем
Через эту последовательность этапов нейросеть обучают предсказывать следующий токен

Когда вы печатаете сообщение, то система предлагает следующее слово. Она делает это, анализируя вероятные комбинации, а не "понимая" вашу мысль
LLM работает примерно так же — только в тысячи раз сложнее
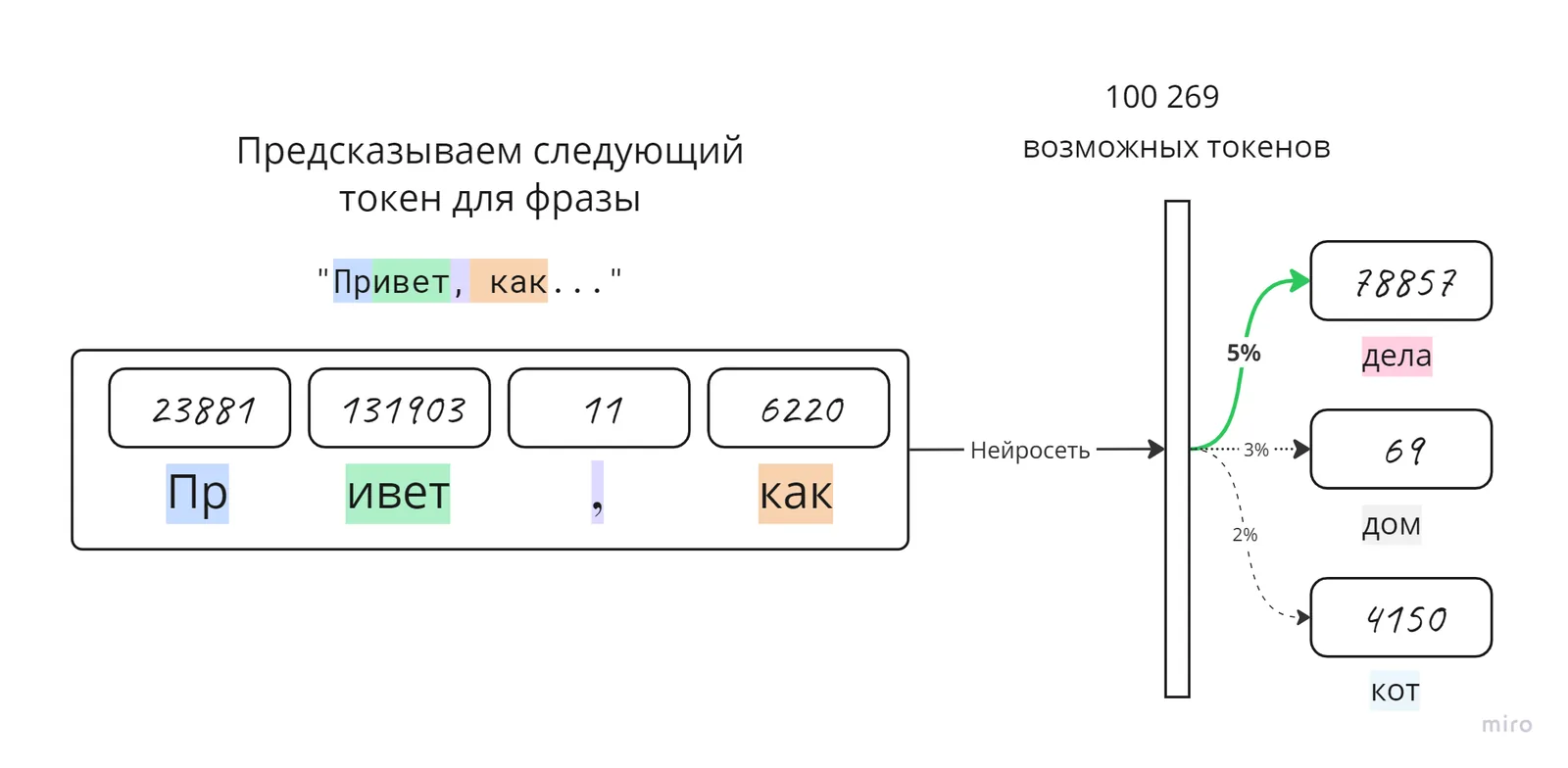
На схеме ниже показана визуализация очень маленькой версии GPT — модели с 85 000 параметров

Для сравнения, GPT-4о использует порядка 1,76 триллиона параметров — это в десятки тысяч раз больше
Каждый параметр — это крошечная настройка веса внутри модели, помогающая ей определять, какое следующее слово или токен будет наиболее вероятным
🔠 Про токены и контекстное окно
🧩 Как работает токенизация
Большие языковые модели вроде GPT не “видят” слова или предложения целиком.
Они оперируют токенами — это фрагменты слов, символы, знаки препинания и пробелы.
Например
Пр ив ет→ 3 токенаК в ар ти ра→ 5 токенов
Здесь можно посмотреть на то, как модель разбивает текст на токены
🧱 Что такое токенизатор
Токенизатор — это "резак", который делит текст на токены.

🧮 В среднем
- 1 токен = 4 символа
- Или ≈ ¾ слова на английском. На русском и других языках модели режут слова чуть похуже
🧪 Пример
Рассмотрим нарезку фразы Привет медвед, как дела? на разных токенизаторах

| Модель | Кол-во токенов | Токенизатор | Особенности модели |
|---|---|---|---|
| GPT-2 | 25 токенов | gpt2 | Почти каждый символ разбивается отдельно. Модель не знает кириллицу. |
| GPT-3.5 / 4 | 11 токенов | cl100k_base | Слово Как уже является цельным токеном |
| GPT-4o / 5 | 8 токенов | o200k_base | Теперь и слово дела превратилось в один токен |
| Модель | Кол-во токенов | Токенизатор | Особенности модели |
|---|---|---|---|
| GPT-2 | 25 токенов | gpt2 | Почти каждый символ разбивается отдельно. Модель не знает кириллицу. |
| GPT-3.5 / 4 | 11 токенов | cl100k_base | Привет и медвед распознаются как цельные фрагменты. Остальное дробится. |
| GPT-4o / 5 | 8 токенов | o200k_base | Более эффективное сжатие, учитывает фразы вроде как дела? |
🧠 Контекстное окно
Контекстное окно — это объем токенов, который языковая модель может удерживать в памяти одновременно во время взаимодействия
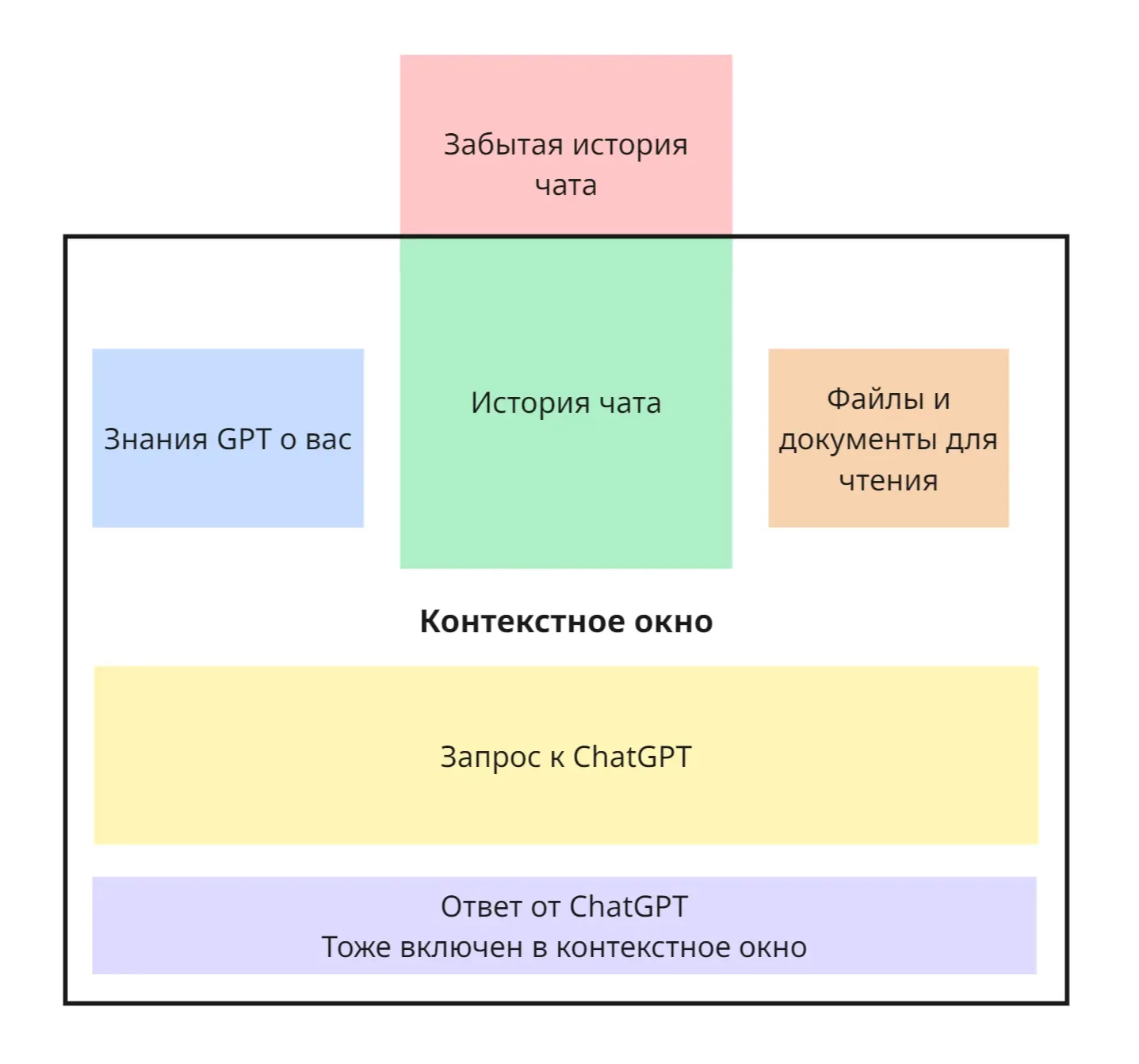
Всё, что помещается в контекстное окно — модель анализирует при генерации следующего ответа
| Модель | Размер контекстного окна | Что помнит |
| GPT-2 | 1 024 | ≈ 750 слов — короткий пост в блоге |
| GPT-3 | 2 048 | ≈ 1 500 слов |
| GPT-3.5 | 4 096 | ≈ 3 000 слов — небольшая статья или аналитический отчёт |
| GPT-4o | 128k | ≈ 96 000 слов — примерно полный роман |
| GPT-5 Chat (актуальная в ChatGPT модель) | 128k | |
| o3 | 200k | |
| o4-mini (high) | 200k | ≈ 150 000 слов — две толстые книги вместе |
| o4-mini | 200k | |
| o1 pro | 200k | |
| GPT-5 nano | 400k | |
| GPT-5 mini | 400k | |
| GPT-4.1 | 1M | ≈ 750 000 слов — весь Властелин колец |
| GPT-4.1 mini | 1M |
🧠 Как работает контекстное окно на практике
Контекстное окно действует как кратковременная память модели
Пока информация находится внутри лимита, модель может её использовать для анализа, запоминания логики и формирования релевантных ответов
Когда ты ведёшь диалог с ChatGPT внутри окна контекста, то модель
- Учитывает историю всего общения
- И формирует ответы, отталкиваясь от всей доступной информации
Но как только ты превышаешь лимит контекста
- Старые данные автоматически вытесняются
- Модель перестаёт помнить то, что было в начале диалога
Это и есть причина, почему иногда ChatGPT забывает, о чём шла речь выше
Проблемы длинных контекстных окон
Большие окна — это не только преимущество. В какой-то момент объем начинает сказываться на качестве ответов и становится слишком дорогим в обработке
Например, у GPT-5 в ChatGPT контекстное окно осталось 128 000 токенов.
💸 Вычислительные затраты
- При удвоении количества токенов нужна в 4 раза большая вычислительная мощность
- Модель должна рассчитывать взаимосвязи между каждым токеном и всеми остальными, а это ресурсоёмко
🎯 Потеря релевантности
- Есть предположение, что модели лучше работают, когда ключевая информация находится в начале или в конце текста
- Если важные детали "спрятаны" в середине длинного ввода, модель может не найти их
💡 Практические советы
- Учитывайте лимит и старайтесь не превышать размер окна, чтобы не терять важную информацию. Например, долгое общение на разные темы внутри одного чата будет ухудшать ответы модели
- Структурируйте текст. Помещайте ключевые факты в начало или в конец вашего запроса — это увеличит шансы на то, что модель не потеряет эту информацию
- Используйте сжатие. Сокращайте и упрощайте текст без потери смысла, чтобы больше важного помещалось в память.
- Рассуждение (Thinking mode) расходует дополнительное место внутри окна контекста, так как в режиме Thinking модель общается сама с собой перед тем, как выдать ответ
Почему GPT модели работают лучше на английском, чем на русском
Вспомним из начала главы, что ChatGPT и подобные трансформеры работают через очень сложный, но одновременно и простой механизм Next Token Prediction
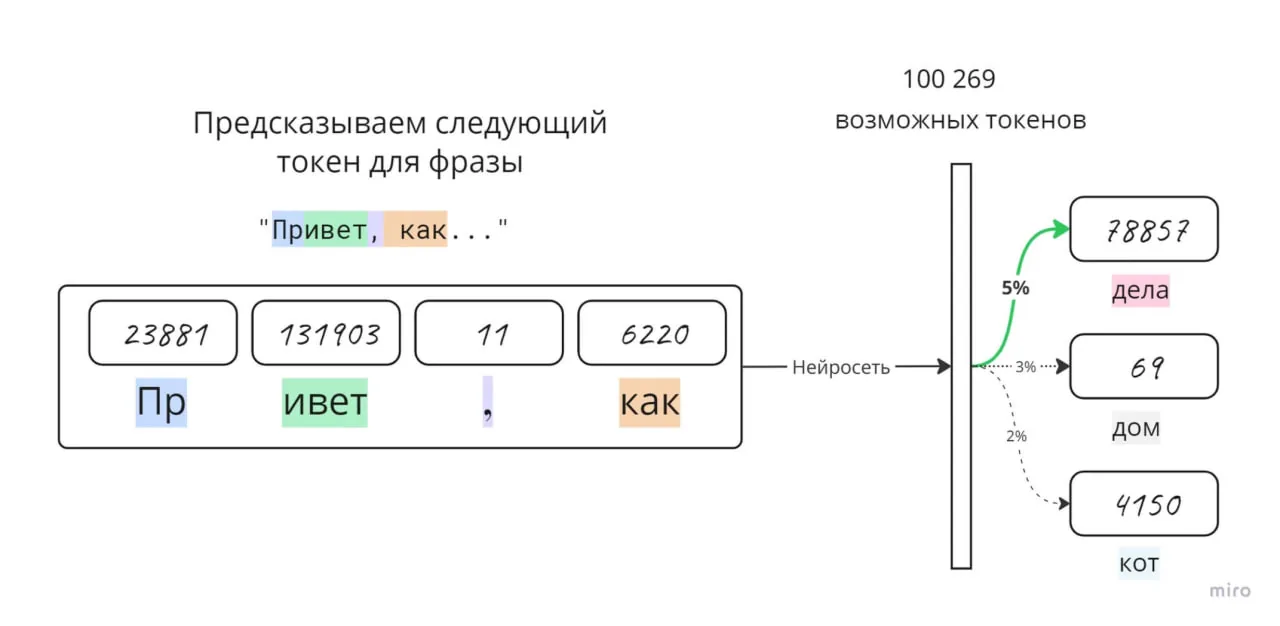
Условная модель обучается через поиск большого количества закономерностей в последовательности бит из текста всего интернета. А затем сжимает их до токенов через специальные токенайзеры.
Ответы модели и ее стиль общения — это по сути повторение паттернов сжатого интернета. Закономерности, которые чаще всего встречались на стадии обучения и будут проявляться при ответах
Проблема порядка слов
Найти закономерности в английском проще, чем в русском. Потому что в русском языке порядок слов не сильно влияет на смысл. Во всех трех вариантах на русском, перевод на английском будет всего лишь один.
Наглядный пример из токенайзера
- "Машина ехала быстро" → 6 токенов
- "Быстро ехала машина" → 6 токенов
- "Ехала машина быстро" → 5 токенов
- "The car was driving fast" → 5 токенов

Все три русские фразы имеют одинаковый смысл, но разную последовательность токенов, что усложняет поиск закономерностей для модели.
Проблема флексий и окончаний
В русском языке есть окончания (флексии), из-за которых GPT воспринимает каждое слово как разное. Хотя для нас слово "Кот" и "Кота" — одно слово.
Примеры в русском языке
Склонение существительных
- Кот (именительный падеж)
- Кота (родительный падеж)
- Коту (дательный падеж)
- Котом (творительный падеж)
Спряжение глаголов
- Я играю
- Ты играешь
- Он играет
- Мы играем
Согласование прилагательных
- Красивая кошка
- Красивого кота
- Красивые коты
- Красивых котов
В английском же красивый — это всегда Beautiful

Почему это проблема для ИИ
В русском одно слово = много форм
- стол, стола, столу, столом, столе, столы, столов, столам, столами, столах
В английском одно слово = 1-2 формы
- table, tables
Для нейросети каждая такая флексия — это отдельный паттерн, который нужно выучить. В русском таких паттернов в разы больше, что усложняет обучение и требует больше данных.
Именно поэтому GPT воспринимает "кот" и "кота" как совершенно разные слова, хотя для нас это одно и то же понятие.
А еще, в русском 6 падежей × 3 рода × 2 числа = 36 основных форм для каждого существительного + множество исключений
В английском же всего 2-4 формы для большинства слов
- cat, cats, cat's, cats'
- В английском: table остается table в 90% контекстов
- В русском: стол может быть столом, столу, столе, столов, столам, столами, столах
Именно поэтому нейросетям проще находить закономерности в английском — меньше вариативности = более предсказуемые паттерны.
Конкретные примеры из токенайзера в русском
- "Кот играл" → "Кот" и "играл" разбиваются на несколько токенов каждое
- "Коты играли" → совершенно другая последовательность токенов
- "Я играл с котом" → слово "котом" токенизируется по-другому, чем "кот"
В английском
- "The cat was playing" → стабильная токенизация
- "The cats were playing" → только добавляется "s" и меняется глагол
- "I was playing with the cat" → "cat" остается тем же токеном

Недостаток обучающих данных 😖
Другой немаловажный параметр — на русском просто меньше материалов, чтобы набрать статистическую значимость
Большинство программистской документации, научных статей и технических ресурсов изначально создается на английском, что дает моделям больше качественных данных для обучения
И как вывод
Русский язык требует больше токенов для выражения того же смысла, что делает его обработку и результаты выдачи менее эффективной.
А презентация GPT 5 показала, что компании уже упираются в тот предел, что качественные текста в интернете тупо закончились, и пора переходить на синтетические данные
🔢 Как большие языковые модели работают с числами
Возможно, ты видел видео, в которых люди ругают ChatGPT, что он не может выполнить простые операции подсчета
И чтобы не быть таким же, давайте посмотрим как модели вообще обрабатывают числа
🧩 Как LLM обрабатывает числа
Токенизация ломает математику
LLM не понимает числа как математические объекты. Вместо этого
- Число "12345" может стать токенами "123" и "45"
- Длинные числа дробятся непредсказуемо
- Разные модели разбивают одно число по-разному
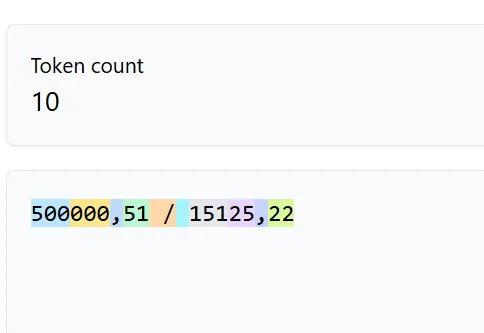
Пример
500000.51 / 15125.22 = ?ChatGPT видит это не как два числа для умножения, а как последовательность токенов, из которых нужно предсказать следующий "наиболее вероятный" токен.
Вот пример того, как для ChatGPT выглядит рассчет числа 500000,51 / 15125,22
Это не два разных числа, а набор из токенов
И модель, основываясь на комбинации этих токенов, должна предсказать следующий токен-ответ
Это работает для простых случаев
- ✅ 2 + 2 = 4 (запомнил из данных)
- ✅ 25 × 4 = 100 (видел много раз)
Но ломается на сложных
- ❌ 847293 × 652847 = ? (такого точно не было в данных)
Вообще то, ChatGPT умеет считать. Но не сам, а через обращение к Python функции. Которая и считает необходимый нам пример
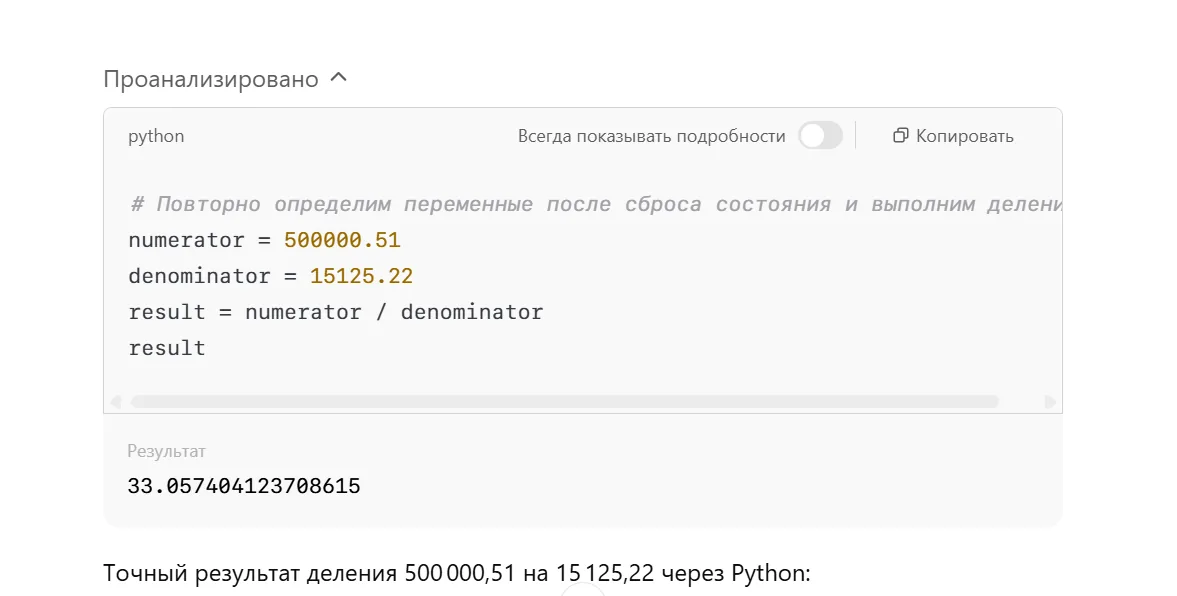
Вот как он считает, если просить его посчитать самому
Вполне хорошо, и ответ вышел правильный, но с небольшой погрешностью


❌ Итого, ChatGPT в расчетах плохо работает с
- Многозначными вычислениями (6+ цифр)
- Точными расчётами и с десятичными дробями
- Любыми операциями, где нужна 100% точность
- Многоэтапными задачами, когда ошибки постепенно накапливаются
Эти пункты актуальны при том условии, что он не обращается к расчету через Python
Как решить ключевые проблемы общения с ChatGPT — 5 рабочих подходов
Ниже я рассказал про 5 практик, которые я использую в таких вот ситуациях ⤵️
😣 ChatGPT отвечает слишком "в общем" и поверхностно
😣 Хочу переработать огромный массив информации с конкретными выводами
😣 Модель генерирует мне банальные или очевидные идеи
😣 Стандартные ответы ChatGPT слишком прямолинейны
😣 Хочу развить и масштабировать свою идею из уже существующей
😣 ChatGPT отвечает слишком "в общем" и поверхностно
Как исправить
Найди релевантный фреймворк, стиль или стандарт в открытых источниках. И попроси ChatGPT сгенерировать ответ, опираясь на этот фреймворк
Вот примеры фреймворков, которые я иногда использую
- SCQA (Situation, Complication, Question, Answer): помогает структурировать презентации так, чтобы сначала задать ситуацию, затем показать проблему, сформулировать вопрос и дать ответ
Используя фреймворк SCQA, помоги мне структурировать презентацию для выхода на новый рынок - PAS (Problem-Agitate-Solution): классическая структура копирайтинга, где сначала обозначается проблема, затем усиливается её значимость, после чего предлагается решение.
Используя фреймворк PAS, помоги мне написать рекламный текст для лендинга нового продукта - Стиль статей New York Times или Wall Street Journal: строгий, структурированный стиль с акцентом на факты и аналитический разбор
Вот структура статьи в стиле New York Times: [вставленный текст]. Напиши обзор моего продукта, используя этот стиль - SMART (Specific, Measurable, Achievable, Relevant, Time-bound): чёткая система для постановки целей
Используя фреймворк SMART, помоги сформулировать 5 целей для моей команды продаж на следующий квартал
Почему это работает ✅
Модель получает чёткий паттерн поведения вместо необходимости "догадываться", что именно от неё требуется
😣 Хочу переработать огромный массив информации с конкретными выводами
Что делать
- Загрузи текст или документ
- Не проси ChatGPT просто "проанализировать" текст без уточнений — это приводит к слишком общим и размытым ответам. Вместо этого сразу укажи конкретную практическую задачу, которую нужно решить. Например:
Изучи этот документ и подготовь бизнес-план для выхода компании на рынок Юго-Восточной Азии
Создай презентацию для инвестора, основываясь на данных из этого отчета
Выдели 5 главных трендов из этого отчета для маркетинговой стратегии
Разработай пошаговый план запуска MVP на основе прикрепленного исследования
Почему это работает ✅
Когда ты формулируешь конкретную цель для ChatGPT, модель получает чёткие рамки задачи. Она больше не обобщает информацию, а подстраивает ответ под твои нужды
- Вместо поверхностного «проанализируй отчёт» проси «создай план выхода бренда на новый рынок»
- Вместо «дай сводку текста» сформулируй «подготовь бизнес-презентацию для инвесторов»
Чем точнее цель, тем более релевантный и полезный результат ты получаешь
😣 Модель генерирует мне банальные или очевидные идеи
Что исправить
- Объясни, как для тебя выглядят идеи уровня 1, 2 и 3
- Попроси идеи только уровня 3 — самые нестандартные и прорывны
Дай мне 5 идей уровня 3 для привлечения B2B-клиентов Идея уровня 1 — рассылка Идея уровня 2 — вебинар
Пример результата идей третьего уровня
- Организация закрытых B2B-экспертных клубов с регулярными живыми сессиями
- Создание персонализированных дашбордов с отраслевой аналитикой для клиентов
- Программа наставничества, где текущие клиенты делятся опытом с новыми
- Локальные бизнес-завтраки с кейс-обсуждениями и участием отраслевых лидеров
- Серия микро-семинаров по новым трендам в отрасли с последующим VIP-нетворкингом
Почему это работает ✅
Модель лучше понимает градацию качества идей и стремится генерировать более глубокие и оригинальные решения
😣 Стандартные ответы ChatGPT слишком прямолинейны
Что делать
- Попроси модель разыграть разные сценарии развития событий — оптимистичный, пессимистичный, реалистичный
- Укажи конкретную область: бизнес, стартап, инвестиции, найм и т.д.
Представь, что мой стартап запускает продукт на рынок Построй три сценария: оптимистичный, пессимистичный и реалистичный. В каждом опиши возможные события, проблемы и итоги
Пример результата
- Оптимистичный сценарий Быстрая адаптация к рынку, превышение прогнозов продаж на 20% за первый квартал, привлечение инвестиций за 2 месяца
- Реалистичный сценарий Постепенное завоевание доли рынка, выход на операционную безубыточность через 18 месяцев, умеренный рост базы клиентов
- Пессимистичный сценарий Сильная конкуренция, необходимость смены бизнес-модели через год, снижение оборота на 30% от целевых показателей
Почему это работает ✅
Модель начинает не просто давать советы, а выстраивать гипотезы развития событий с разными углами зрения
😣 Хочу развить и масштабировать свою идею из уже существующей
Что делать
- Сначала задай одну краткую идею
- Попроси ChatGPT расширить её на 5–10 способов применения, целевых аудиторий или форматов
Вот моя базовая идея: создать AI-ассистента для поиска книг. Расширь эту идею: придумай 10 вариантов, как её можно монетизировать или адаптировать под разные рынки
Почему это работает ✅
Модель выходит за рамки первой мысли и помогает увидеть масштаб и потенциал базовой задумки.
Хочешь не просто читать про AI, а собрать свой продукт с Claude Code, Cursor и агентами? Раз в месяц я беру 10 человек на поток и провожу через 6 уровней.
Занять место